
はじめに
こんにちは。サーバーサイドエンジニアの近藤です。
先日、私が担当している MedPeer (医師・医学生向け医療情報サイト) にて負荷試験環境を構築しました。
本記事ではその取り組みについてご紹介します。
背景
MedPeer ではユーザーである医師会員向けに、薬剤情報などの講演会を生放送で配信するための、Web講演会というサービスを提供しています。
このWeb講演会サービスでは、講演会の終了時刻付近に講演会のアンケートフォームが開くことで、総リクエスト数が急増する傾向があります。
大量アクセスによるシステムの負荷上昇が懸念され、同時間帯に開催できる講演会数に制限があることがビジネス上の課題でした。
そこで、許容できるWeb講演会の開催規模を定量的に計測し、システム改修によってその上限を引き上げることを目的に、このたび負荷試験環境を構築する運びとなりました。
また、将来的に機能やインフラの追加・改修を行う際に、性能への影響を事前に評価できる環境を整えたいという目的もありました。
開発の指針
負荷試験環境の開発にあたり、下記の3つの指針を定めて開発を進めていました。
- 誰でも安全に負荷試験をできる環境が用意されていること
- 負荷試験の実施において複雑な手順やインフラの専門的な知識を要求されず、メンバーの誰もが負荷試験を実施できる環境を目指しました
- 計測したい負荷 (Web講演会の同時開催時の大量アクセス) を正しくかけることができ、その負荷を計測できるようになっていること
- 試験結果の信頼性を担保するため、Web講演会のピーク時に発生する複雑なアクセスパターンを忠実に再現できるよう、実装における工夫を取り入れました
- まずは最低限動く状態を目指して作ること
- 最初から完璧な環境を目指すのではなく、まずは主要な課題を解決できる最小限の構成を目指しました
開発において判断に迷った際はこの指針を基に意思決定を行いました。
システムの概要
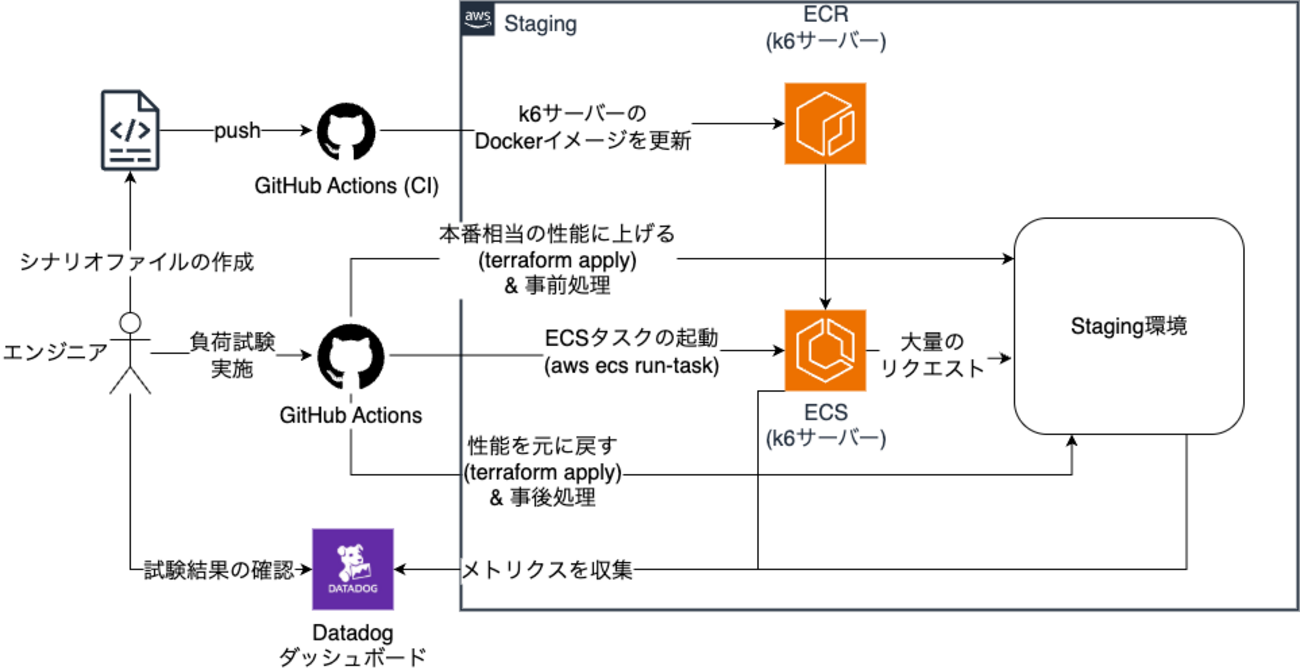
全体像
今回の負荷試験は、既存の Staging 環境を「試験中だけ本番環境相当にする」というコンセプトで行います。
具体的には、試験の実行中のみインフラの性能を本番環境と同等まで一時的に引き上げ、その環境に対して大量のリクエストを送信することで負荷試験を行います。

各要素の役割
- 負荷生成 (k6 サーバー)
- 負荷生成ツールには k6 を採用しました。専用サーバー上で k6 を実行し、シナリオファイル(リクエスト内容を定義したファイル)に基づいて試験対象へリクエストを送信します
- 自動化 (GitHub Actions)
- 試験の準備から実行、後片付けまでの一連のフローは GitHub Actions Workflow で自動化し、誰でも手軽に試験を実施できる体制を整えました
- モニタリング (Datadog)
- 試験中の主要なメトリクスは Datadog のダッシュボードでリアルタイムに可視化し、試験結果をすぐに確認できるようにしています
- ダミーデータの準備
- より本番に近い状態で試験を行うため、インフラ性能だけでなくデータベースの状態も重要です。システム構成図には記載がありませんが、事前に Staging 環境のデータベースへ大量のダミーデータを投入し、本番環境のデータ規模を再現しました
各システムの構成
ここからは、負荷試験環境を構成する各要素について、その詳細や採用理由などを解説します。
負荷試験環境のインフラ構成
スケールアップ対象の要素
負荷試験の実施中は、主に以下の要素を本番環境と同等の設定値へ変更します。
- アプリケーションサーバー (Amazon ECS)
- タスク数
- CPU・メモリの割り当て量
- Web サーバー (Unicorn)
- データベース (Amazon RDS)
- インスタンスサイズ
実装方式
この動的な環境変更は、Terraform の Input変数機能を使って実現しました。
インフラ構成に load_test_mode という真偽値 (boolean) の変数を定義しました。この変数を true にすると、Terraformの三項演算子によって各リソースが本番環境相当の設定値で再構築される仕組みです。
resource "aws_db_instance" "rds" { instance_class = var.load_test_mode ? (本番環境の設定値) : (Staging環境の設定値) ...
設計上の判断と見送ったこと
開発速度とコストのバランスを考慮し、以下の2つの判断を行いました。
- 実装コストを考慮した初期スコープの絞り込み
- 完全な環境再現には多大なコストがかかるため、まずはアプリケーションとデータベースといった主要な要素にスコープを絞りました。Redis などのキャッシュサーバーについては、試験結果からボトルネックとして顕在化した場合に、次のステップで対応する方針としています。
- 既存の Staging 環境の活用
- 負荷試験専用の環境をゼロから構築する案もありましたが、実装工数の増大が懸念されたため見送りました。既存の Staging 環境を活用することで、迅速に試験環境を準備できました。
負荷発生サーバーのインフラ構成
負荷を発生させる k6 の実行環境は、試験対象のアプリケーションサーバーとは完全に分離された、専用の Amazon ECS タスクとして構築しました。
実行の仕組みと性能設計
負荷試験の実行フローは以下の通りです。
- CI/CD パイプラインで、k6 本体とシナリオファイルを含む Docker イメージを事前にビルドします。
- 試験実行時には、このイメージからコンテナを起動し、内部で
k6コマンドを実行する仕組みです。
サーバーのスペック(CPU, メモリ)は、k6 の公式ドキュメントを参考に決定しました。ドキュメントでは 1VU (仮想ユーザー) あたり約 1〜5MB のメモリを消費するとされており、これを基準に、想定する負荷量に対して十分なリソースを割り当てています。
Datadogとの連携
MedPeer ではモニタリングツールとして Datadog を採用しています。
ですが k6 から Datadog へのメトリクス送信は、標準ではサポートされていません。
k6 の公式ドキュメントを参考にし、StatsD プロトコルでメトリクスを送信できる拡張機能 (xk6-output-statsd) を組み込んだ k6 をビルドして使うようにしました。
JMeter・Grafana Cloud k6 との比較
k6 の他の主流な負荷試験用ツールとして、JMeter を利用する選択肢もありました。ですが JMeter はGUIのソフトウェアであることや、シナリオに XML ファイルを利用するためロジックの記述・再利用が難しそうなこと、k6 よりもメモリ使用量等のパフォーマンスが悪いことなどの理由から、k6 を選択しました。
また、k6 の実行環境として SaaS である Grafana Cloud k6 の利用も検討しましたが、実施コストを比較した結果、今回は自社環境にセルフホストする方式を選択しました。
実施コスト
負荷試験1回あたりの金銭コストとしては、模倣する本番環境やかける負荷の量次第ではありますが、今回構築した負荷試験環境・シナリオの場合、4時間の負荷試験環境の立ち上げで75$ほどのコストとなりました。Staging 環境の ECS サーバーと k6 を動かすサーバーの費用が大部分を占めているため、予めある程度はコストの予測ができると思います。
自動化された負荷試験ワークフロー
負荷試験の一貫性と再現性を担保するため、準備から片付けまでの一連のプロセスを GitHub Actions で自動化しました。これにより、誰でも安全かつ手軽に試験を実施できます。
ワークフローは、大きく分けて以下の4つのフェーズで構成されます。
1. 準備
まず、試験実行に伴う不要なアラートを防ぐため、Staging 環境の監視ツールを一時的に停止します。その後、Terraform を通じて環境を本番相当のスペックへスケールアップします。
name: Setup Load Test Environment on: workflow_dispatch: jobs: ... setup-load-test: steps: ... - name: terraform plan ... env: TF_VAR_load_test_mode: ${{ vars.STG_LOAD_TEST_MODE }} - name: terraform apply ...
2. 実行
次に、負荷試験本体を実行します。このフェーズでは、純粋な負荷生成だけでなく、試験データの整合性を保つための処理も自動化しています。
- データ準備・リセット: 試験シナリオによっては、特定のデータベースレコードの作成、更新、削除が必要です。これらの処理は Rake タスクとして定義し、k6 の実行前後で自動的に実行することで、常にクリーンな状態で試験を開始・終了できるようにしています
- 負荷試験の実行: 事前にビルドされた Docker コンテナを起動し、内部で k6 コマンドを実行して負荷を発生させます
name: Run Load Test on: workflow_dispatch: inputs: ... jobs: before-load-test-task: steps: - name: Execute Before Test Rake Task run: | aws ecs run-task ... "command": [ "bundle", "exec", "rake", "load_test:'${{ github.event.inputs.test_scenario }}':before_test" ] ... run-load-test: steps: - name: Execute k6 Scenario on ECS Task run: | ... aws ecs run-task ... "command": [ "k6", "run", ... "load_test/${{ github.event.inputs.test_scenario }}.js" ] ... after-load-test-task: steps: - name: Execute After Test Rake Task run: | ...
3. 片付け
試験終了後、停止していた監視ツールを再開し、スケールアップした Staging 環境の性能を元の状態へ戻します。
name: Cleanup Load Test Environment on: workflow_dispatch: jobs: ... cleanup-load-test: steps: ... - name: terraform plan ... env: TF_VAR_load_test_mode: ${{ vars.STG_LOAD_TEST_MODE }} - name: terraform apply ...
4. 確認
最後に、Datadog のダッシュボードで試験結果を評価します。
分析を効率化するため、ダッシュボードには2つの工夫を加えました。
- Staging/本番兼用ダッシュボード: ダッシュボードの変数機能を活用し、本番環境のモニタリングで普段から使っているダッシュボードをそのまま負荷試験にも流用しています。これにより、環境を切り替えるだけで同じ指標を比較できるようになります
- k6 専用ダッシュボード: 上記とは別に、負荷サーバー自体の CPU 使用率や k6 が収集したメトリクス(リクエスト数、レスポンスタイム等)を可視化する専用ダッシュボードも用意し、k6 サーバー側が過負荷に陥っていないかを手軽に確認できるようにしました

シナリオファイルの作成
負荷試験のシナリオファイルは、「どのようなリクエストを、どのくらいの量・頻度で送るか」を定義します。このセクションでは、実際のトラフィックを再現するためのシナリオ作成プロセスと、実装上の工夫について解説します。
リクエストパターンの調査
最初に、負荷試験の対象とする状況(例:講演会終了間際のピーク時)を定め、その時間帯のアクセスログを分析します。ここでの目的は、リクエストの総量だけでなく、時間経過に伴うリクエスト数の増減パターン(トラフィックの波形)を把握することです。このパターンを基にシナリオを作成します。
シナリオファイルの実装
次に、分析結果を基に k6 のスクリプトを作成します。http.get や sleep を組み合わせてシナリオを記述します。
export default function () { http.get(`${host}/top`) sleep(1) http.get(`${host}/about`) }
実装時には、負荷試験特有の注意点があります。
- POST リクエストにおける CSRF トークンの処理を忘れないこと
- 意図しない外部ドメインへのリダイレクトを防止すること
このような問題を特定しやすくするため、最初は 1 VU など、ごく少数のユーザーから試験を開始するのが有効です。
dry-run モードの導入
「ユーザーごとにリクエストタイミングをずらす」などの複雑な要件が加わると、コードから意図したリクエストパターンが生成されるかを確認するのは困難です。
この課題に対し、シナリオスクリプトに dry-run モードを導入しました。これは、HTTPリクエストや sleep を実際には実行せず、予定されていたリクエストのログを高速に出力する機能です。
- sleep 処理の代替: dry-run モード時は、実際の待機処理をスキップし、内部で管理する論理的な時刻のみを進めます
- HTTP リクエスト処理の代替: HTTP リクエストも実際には送信せず、予定時刻や URL といった情報を記録するのみとします
- 結果の比較: dry-run の実行後、記録されたログを集計・グラフ化します。このグラフを、最初に調査した実際のトラフィック波形と比較することで、シナリオの妥当性を事前に検証します。

宣言的なシナリオ定義
複雑なリクエストパターンをループと sleep で記述する命令的な方法は、変更が全体に影響しやすく、メンテナンス性に課題がありました。
この問題に対し、より直感的にシナリオを定義できる宣言的なアプローチを導入しました。これは、再現したいトラフィックの波形を、アスキーアートで描くように定義することで、そこから各リクエストのタイミングが自動算出される仕組みです。
const topPageAccessDistribution = distribution(` ### ##### ########## ####### #### ## `)
実装の詳細は控えますが、このアプローチにより、複雑なシナリオの可読性とメンテナンス性が向上したと思います。
負荷試験環境の活用
負荷試験環境を利用して早速、本番環境では過去に事例が無い規模のアクセスピークを模した負荷試験を実施しました。
これにより、現行システムの性能上限と、システム増強によってどの程度性能を向上できるかの見込みを、定量的に把握できました。
また、今後は新規機能の追加やインフラ構成を変更する際に、性能への影響を事前に計測する環境としても負荷試験環境を活用できます。
この環境の構築により、システムの負荷を定量的に把握できるようになっただけでなく、試験実施にかかる検証コストも大幅に削減できました。
おわりに
これからも負荷試験の知見を活かしながら、安定したサービス提供と事業の成長の基盤となる仕組みづくりを続けていきます。
本負荷試験環境構築プロジェクトは、筆者の他にサーバーサイドエンジニア2名とSRE2名、技術顧問をしていただいた外部のアドバイザーの方1名、その他多くの方々のご協力により完了させることができました。ご協力いただいた皆様に改めて感謝いたします。
最後までお読みいただきありがとうございました。
是非読者になってください!
メドピアでは一緒に働く仲間を募集しています。
ご応募をお待ちしております!
■募集ポジションはこちら
medpeer.co.jp
■エンジニア紹介ページはこちら
engineer.medpeer.co.jp
■メドピア公式YouTube
www.youtube.com
■メドピア公式note
style.medpeer.co.jp
{kind=link}
コメント