

「Linuxカーネル2.6解読室」(以降、旧カーネル解読室)出版後、Linuxには多くの機能が追加され、エンタープライズ領域をはじめとする様々な場所で使われるようになりました。
それに伴いコードが肥大かつ複雑化し、多くのエンジニアにとって解読不能なブラックボックスとなっています。
世界中のトップエンジニア達の傑作であるLinuxカーネルにメスを入れ、ブラックボックスをこじ開けて、時に好奇心の赴くままにカーネルの世界を解読する「新Linuxカーネル解読室」プロジェクト。
執筆者 : Ryo Takakura
※ 「新Linuxカーネル解読室」連載記事一覧はこちら
遅延処理の仕組みであるWorkqueue (WQ) について紹介したいと思います。WQは旧カーネル解読室でも解説されていますが、その実装は当時 (v2.6) から大きく変わっています。本記事では、当時のWQ (以後旧WQ) が現在の実装に至るまでを、背景等を交えながら紹介できればと思います。なお本記事は、筆者がWQを調べていて面白いと感じたことをまとめたような記事です。読者の方が本記事を通してWQに興味を持って頂けたら嬉しいです。
WQは、Linuxにおいて用意されている遅延処理の仕組みの一つです。遅延処理を行う目的は、ソフト割り込みのようなハード割り込みの処理を遅延させカーネルの応答性を向上させるためであったり、NMIのようにコンテキスト自体に制約 (ロック取得など) があり他コンテキストに処理を委譲する必要があったりと様々です。WQは、処理をプロセスコンテキストへ遅延するために提供されている仕組みです。各種デバイスドライバやファイルシステムのIOなどカーネルで幅広く使われています。処理を実行するスレッドはワーカースレッド、実行される処理はワークアイテムと呼ばれます。本記事では、このワーカースレッドがワークアイテムを実行するまでの仕組みを、まずは比較的シンプルに実装されていた旧WQにおいて確認したいと思います。その後、現在のWQのベースとなるConcurrency Managed Workqueue (CMWQ) が取り込まれた直後の実装を参照しながら、WQにおける “Concurrency Management” についておさらいしたのち、旧WQと比較する形でその必要性を確認していきます。現在のWQの実装と直近のWQにおける取り組みについても、最後に簡単に紹介できればと思います。なお記事では、alloc_workqueue(), destroy_workqueue() 等で操作の対象となる “workqueue” は、システムとしての”WQ”と区別して使用しています。
WQでは、v2.6.36において取り込まれたCMWQ以前の実装をLegacy Workqueue (旧WQ)、以降の実装をConcurrency Managed Workqueue (CMWQ) として区別しています。本章では、旧WQの実装および当時挙げられていた旧WQの課題を確認したいと思います。なお、本章が解説のベースとするバージョンはv2.6.35です。
workqueue_struct構造体
workqueue_struct構造体は、旧WQから現在に至るまで、各workqueueに割り当てられるワーカースレッドとワークアイテムを管理する役割を担ってきた構造体です。ここでは、旧カーネル解読室 (旧WQ) のworkqueue_struct構造体の説明をそのまま参照してみたいと思います。workqueue_struct構造体の考え方は、旧カーネル解読室当時から基本的に変わっていませんが、旧WQとCMWQにおける大きな違いとして割り当てられるワーカースレッドが挙げられます。そのため、本記事のテーマは、(ざっくりと) workqueueに対するワーカースレッドの割り当て方の変遷です。
workqueueは、workqueue_struct構造体の配列で、目的ごとに専用のworkqueueを用意しています。それぞれのCPU用のエントリを持ち、そのCPU上で実行すべき処理 (work_struct構造体) を複数登録できます。
各workqueue_struct構造体には、専用のカーネルスレッドが割り当てられています。おのおののスレッドは、属しているworkqueue_struct構造体に登録されている処理を (work_struct構造体) を実行する役目を受け持ちます。マルチプロセッサシステムの場合、それぞれのCPU用に専用のカーネルスレッドを用意しています。
workqueueの作成から実行まで
先の旧カーネル解読室の説明を、実際に当時の実装を参照しながら確認したいと思います。以下は、旧WQにおけるworkqueue_struct構造体を確保するAPI (create_workqueue()) の延長で呼ばれる__create_workqueue_key()の実装になります。旧カーネル解読室の説明にもあった通り、ワーカースレッドはworkqueue専用・CPU毎 (L.1035) に確保されること (L.1039) が分かります (以後Multi Threaded (MT))。Single Threaded (ST) なworkqueueの場合 (L.1014) には、CPU毎のワーカースレッドの割り当ては行われず、システム全体に対して一つのワーカースレッドがworkqueue専用に確保されます (L.1016)。
986 struct workqueue_struct *__create_workqueue_key(const char *name, 987 int singlethread, 988 int freezeable, 989 int rt, 990 struct lock_class_key *key, 991 const char *lock_name) 992 { 993 struct workqueue_struct *wq; 994 struct cpu_workqueue_struct *cwq; 995 int err = 0, cpu; 996 997 wq = kzalloc(sizeof(*wq), GFP_KERNEL); 998 if (!wq) 999 return NULL; 1000 1001 wq->cpu_wq = alloc_percpu(struct cpu_workqueue_struct); ... 1009 wq->singlethread = singlethread; 1010 wq->freezeable = freezeable; 1011 wq->rt = rt; ... 1013 1014 if (singlethread) { 1015 cwq = init_cpu_workqueue(wq, singlethread_cpu); 1016 err = create_workqueue_thread(cwq, singlethread_cpu); 1017 start_workqueue_thread(cwq, -1); 1018 } else { ... 1035 for_each_possible_cpu(cpu) { 1036 cwq = init_cpu_workqueue(wq, cpu); 1037 if (err || !cpu_online(cpu)) 1038 continue; 1039 err = create_workqueue_thread(cwq, cpu); 1040 start_workqueue_thread(cwq, cpu); 1041 } 1042 cpu_maps_update_done();
以下は、ワークアイテムをqueueするためのAPIであるqueue_work()の実装です。ワークアイテムは、MTの場合にはqueueされたCPU (L.288) においてqueueされた順に処理され、STの場合にはCPUグローバルにqueueされた順に処理されます。このワークアイテムがqueueされたCPUにおいて処理される点は、WQの仕様として当時から現在に至るまで変わっていません。queueされたワークアイテムは、queueに伴い起床したworkqueueに紐づく (MTの場合にはCPU毎な) カーネルスレッドによって実行されます。
なお当時のMTとSTの使い分けとしては、CPUグローバルにワークアイテムを逐次実行する必要がある等の場合にはSTが使用され、特に明示的な理由がない場合はMTなworkqueueが使用されていたようです。
284 int queue_work(struct workqueue_struct *wq, struct work_struct *work) 285 { 286 int ret; 287 288 ret = queue_work_on(get_cpu(), wq, work); 289 put_cpu(); 290 291 return ret; 292 } 293 EXPORT_SYMBOL_GPL(queue_work);
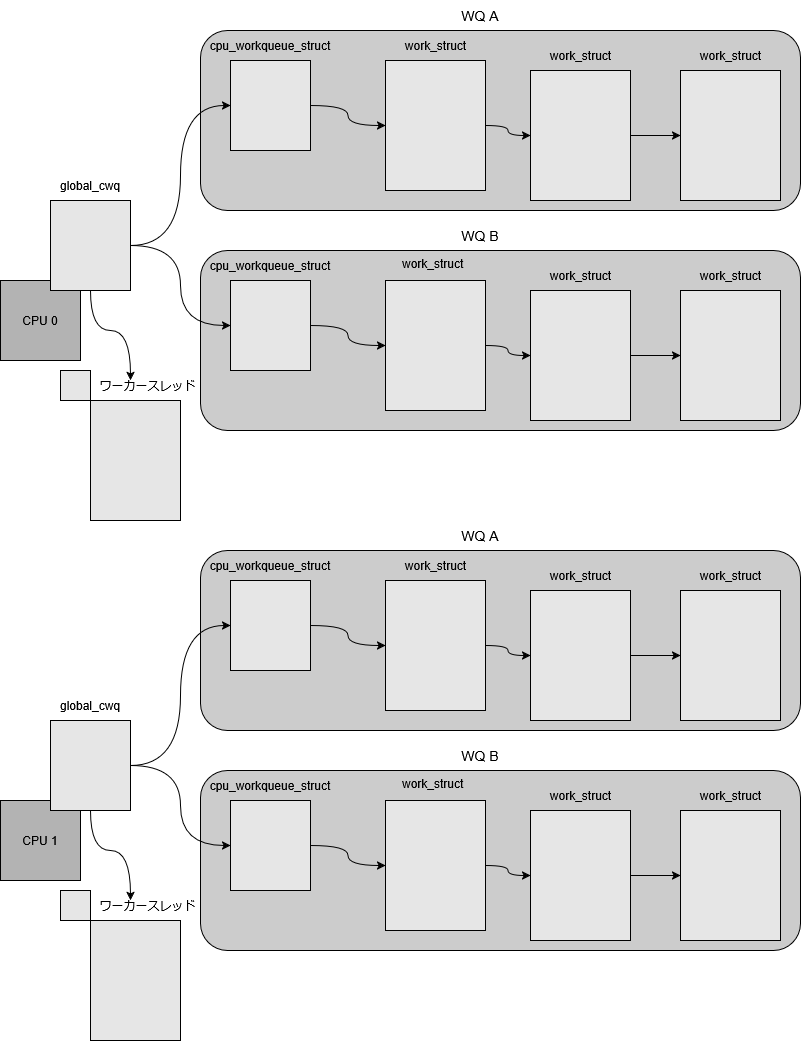
以下は、MTにおけるworkqueueとワーカースレッド・ワークアイテムの関係を示した図です。CPU毎のワーカースレッドがworkqueueごとに割り当てられていることがわかります。

旧WQにおける課題
次章でCMWQを紹介するにあたり、ここまでで簡単に確認した旧WQの特徴を踏まえて、当時挙げられていた旧WQの課題をいくつか紹介したいと思います。
増えすぎたワーカースレッドとその弊害
Linuxでは、システムにおける最大PID数のデフォルトは32Kとなっています。前節で確認した通り、旧WQではworkqueueごとにワーカースレッドが確保され、MTの場合にはさらにCPUの数だけ確保されます。このことから、システムのCPU数増加に伴うワーカースレッドの増加によるPIDの枯渇が問題となりました。この増えすぎたワーカースレッドは、PID等のリソース消費の原因になる他、ワーカースレッド間におけるコンテキストスイッチの増加など性能を低下させる原因となります。
また、MTにおいてCPUごとに割り当てられるワーカースレッド間では、お互いのワークアイテムの実行状況は連携されず、ワークアイテムはqueueされたタイミングに応じて各CPUのワーカースレッドによって独立に処理されていました。これは、ワークアイテム間に依存関係はあるが、マルチコアなシステムにおける並列性を生かしたいユーザーにとって並列性(MT)と逐次実行(ST)のトレードオフの問題となってしまいます。もしこのトレードオフに縛られず、ワークアイテム間の依存関係を考慮しながら並列に処理を実行したい場合には、当時のfs/ceph/messenger.cにおいて実装されているような、ワークアイテムの実行状況をトラッキングするような独自の仕組みを実装する必要があります。
次章では、このユースケースにみられるようなユーザーが多くを考慮する必要があった旧WQの側面を踏まえながら、CMWQにおけるConcurrency Managementの実装と必要性について確認したいと思います。なお、net/ceph/messenger.cの独自Concurrency Managementについては、CMWQにおいてcommit f363e45fd1184 (“net/ceph: make ceph_msgr_wq non-reentrant”) で解消されているので、気になる方は次章を読んだ後に確認してみてください。
概要
現在のWQであるConcurrency Managed Workqueue (CMWQ) は、前章で確認した旧WQにおける課題を踏まえた Concurrency Managed なWQです。しかし、CMWQがv2.6.36で実装されてから現在に至るまで、WQには様々な修正が入っています。そのため、まず本章では旧WQとの比較が容易なCMWQ実装直後のv2.6.36をベースに、CMWQが旧WQと比較して Concurrency Managed であることを確認したいと思います。現在のWQについては、本章でCMWQが旧WQと比較して Concurrency Managed であることを確認した上で、最後に簡単に紹介したいと思います。
Concurrency Managementとは
前章では、旧WQにおいてワーカースレッドが、workqueueごとに確保されることを確認しました。CMWQにおいては、workqueueごとにワーカースレッドは確保されず、あらかじめ用意されているworkqueue globalなワーカースレッドが割り当てられます。このworkqueue globalなワーカースレッドは、CMWQで新たに導入されたper cpuなglobal_cwq構造体 (以降gcwq) に紐付けられています。gcwqには、ワーカースレッドに加えて、ワークアイテムもworkqueueに関わらず紐付けられます。そのため、旧WQにおいてworkqueueごとに管理されていたワークアイテムやワーカースレッドは、CMWQではCPU単位で管理されます。
143 148 struct global_cwq { 149 spinlock_t lock; 150 struct list_head worklist; 151 unsigned int cpu; 152 unsigned int flags; 153 154 int nr_workers;
以下は、WQを確保する際に呼ばれる__alloc_workqueue_key()の抜粋です。旧WQの__create_workqueue_key()と比較すると分かるとおり、CMWQにおいてはworkqueueごとの新たなワーカースレッドの確保は行われず、per cpuなgcwqが紐付けられるのみ (L.2799) となります。
2757 struct workqueue_struct *__alloc_workqueue_key(const char *name, 2758 unsigned int flags, 2759 int max_active, 2760 struct lock_class_key *key, 2761 const char *lock_name) 2762 { 2763 struct workqueue_struct *wq; 2764 unsigned int cpu; ... 2794 for_each_cwq_cpu(cpu, wq) { 2795 struct cpu_workqueue_struct *cwq = get_cwq(cpu, wq); 2796 struct global_cwq *gcwq = get_gcwq(cpu); 2797 2798 BUG_ON((unsigned long)cwq & WORK_STRUCT_FLAG_MASK); 2799 cwq->gcwq = gcwq; 2800 cwq->wq = wq; 2801 cwq->flush_color = -1; 2802 cwq->max_active = max_active; 2803 INIT_LIST_HEAD(&cwq->delayed_works); 2804 }
ここまでを整理すると、旧WQではworkqueueごとに割り当てられていたワーカースレッドは、CMWQでは以下図のように各CPUにworkqueue globalに割り当てられます。次節では、このgcwq導入に伴うworkqueueとワーカースレッドの関係を踏まえて、前章で挙げた旧WQの課題がどのようにCMWQにおいて解消されたかを確認します。
Concurrency Managementの具体例
Concurrency Managementに求められる要件は、以下ドキュメンテーションにもある通り、ワーカースレッド (Execution Context) が必要以上 (minimal) に存在せず、かつ実行が滞りなく (sufficient) 行われることです。本節では、このExecution Contextであるワーカースレッドがminimal but sufficient levelな状態であるという要件が満たされない具体的なケースを通して、Concurrency Managementについて考えてみたいと思います。
(Documentation/core-api/workqueue.rst)
For any thread pool implementation, managing the concurrency level
(how many execution contexts are active) is an important issue. cmwq
tries to keep the concurrency at a minimal but sufficient level.
Minimal to save resources and sufficient in that the system is used at
its full capacity.
WQ_CPU_INTENSIVE
まずは、実行時間が長いワークアイテムAと、ワークアイテムAとは異なるworkqueueに属するワークアイテムBが同じCPUにqueueされた状態を考えてみます。この場合、ワークアイテムBは、ワークアイテムAの完了を待ち続けることになります。旧WQにおいては、各WQが各々のワーカースレッドを割り当てられていたこと (Execution contextがmore than sufficient, resourceがwastedな状態) から、ワークアイテムAの処理に時間がかかるような場合でも、処理しているワーカースレッドはシステムのスケジューラによりスケジュールアウトされ、いずれワークアイテムBを処理するためのワーカースレッドがスケジューリングされました。しかし、CMWQにおいては、ワーカースレッドが共有されることから、旧WQのようにスケジューラ頼みではワークアイテムBは実行されません。このようなExecution Contextがless than sufficientな状態になった場合、新たなExecution Context (ワーカースレッド) が必要となります。WQ_CPU_INTENSIVEは、このワークアイテムAのような実行時間がかかるであろうとされるワークアイテムに対して用いられるフラグとなります。これから実行されるワークアイテムがWQ_CPU_INTENSIVE指定されていた場合 (L.1813) には、続くワークアイテムを処理するための新たなワーカースレッドを起床します (Execution Contextをminimal but sufficient levelな状態に保つ)。
1750 static void process_one_work(struct worker *worker, struct work_struct *work) ... 1809 1813 if (unlikely(cpu_intensive)) 1814 worker_set_flags(worker, WORKER_CPU_INTENSIVE, true);
起床するかどうかの判定が行われるworker_set_flags()では、このワーカースレッド以外のローカルCPUにおけるワーカースレッドの有無 (L.755)・処理待ちのワークアイテムの有無 (L.756) を確認します。ローカルCPUで実行されているワーカースレッドが無く、処理待ちのワークアイテムが有る場合には、新たにワーカースレッドを起床します (L.757) 。
738 static inline void worker_set_flags(struct worker *worker, unsigned int flags, 739 bool wakeup) 740 { 741 struct global_cwq *gcwq = worker->gcwq; 742 743 WARN_ON_ONCE(worker->task != current); 744 745 750 if ((flags & WORKER_NOT_RUNNING) && 751 !(worker->flags & WORKER_NOT_RUNNING)) { 752 atomic_t *nr_running = get_gcwq_nr_running(gcwq->cpu); 753 754 if (wakeup) { 755 if (atomic_dec_and_test(nr_running) && 756 !list_empty(&gcwq->worklist)) 757 wake_up_worker(gcwq); 758 } else 759 atomic_dec(nr_running); 760 } 761 762 worker->flags |= flags; 763 }
ワークアイテムがsleepした場合
Execution Contextがminimal but sufficient levelな状態ではなくなる他のケースとして、ワークアイテムがsleepした場合が挙げられます。この場合、前節と同様にCMWQにおいてワーカースレッドがworkqueue間で共有されていることから、sleepしたワークアイテムに続くワークアイテムは処理されません。このようなワークアイテムのsleepに伴うExecution Contextがless than sufficientな状態になった場合のため、CMWQではスケジューラに対してフックを用意しています。スケジューラでは、sleep状態に移行するスレッドがワーカースレッドである場合 (L.3778)、新たにワーカースレッドを起床するかどうか確認します (L.3782)。wq_worker_sleeping() (L.3781)では、worker_set_flags()同様の確認を行い、ローカルCPUで実行されているワーカースレッドが無く、処理待ちのワークアイテムが有る場合には、新たにワーカースレッドを起床します (L.3783)。
3739 3742 asmlinkage void __sched schedule(void) ... 3772 3778 if (prev->flags & PF_WQ_WORKER) { 3779 struct task_struct *to_wakeup; 3780 3781 to_wakeup = wq_worker_sleeping(prev, cpu); 3782 if (to_wakeup) 3783 try_to_wake_up_local(to_wakeup); 3784 }
現在のWQ
前節において紹介したCMWQでは、workqueueにはあらかじめworkqueueグローバルに確保されているワーカースレッドが割り当てられ、workqueueに割り当てるワーカースレッドのnice値といった属性をユーザーが指定することはできませんでした。しかし、現在のWQでは/sys/devices/virtual/workqueue/WQ_NAME/やapply_workqueue_attrs()を通して、workqueueに割り当てるワーカースレッドの属性を指定・変更することできます。ユーザーから指定された属性を保持するワーカースレッドが存在しない場合には、新たに指定された属性を保持するワーカースレッドが作成されます。
$ ls /sys/devices/virtual/workqueue/writeback/ affinity_scope affinity_strict cpumask max_active nice per_cpu power subsystem uevent
そのため、現在のWQにおけるConcurrency Managementは属性を共有しているワーカースレッド間で行われます。なお、各ワーカースレッドとCPUの関係はこれまでと変わらないため、前節で紹介した主な構造体は、現在のWQにおいては以下のように対応しています。
struct global_cpu_workqueue -> struct worker_pools struct cpu_workqueue_struct -> struct pool_workqueue
異なる属性が与えられたワーカースレッドが2つある場合 (ATTR 1とATTR 2) には、それぞれのワーカースレッドとCPUの対応は以下のようになります。

本記事では、WQの現在の実装に至るまでの経緯を辿ってきました。最後に、WQが導入されるに至った背景それ自体について、昨年のtaskletに関する取り組みを交えて余談的に取り挙げたいと思います。
WQへのtasklet統合
これまでにもtaskletについては、リファクタリングが必要として度々議論が行われてきましたが、WQに統合されるという形で昨年 (ついに?) 手が加えられました。taskletが導入されるに至った経緯を遡ると、旧カーネル解読室にも説明されているように、WQとは切り離せない関係にあります。
Linuxカーネル2.4以前は、taskqueueと呼ばれる遅延処理の仕組みが利用されていました。割り込みコンテキストの遅延処理もプロセスコンテキストの遅延処理も、このtaskqueueを利用して実現していました。Linuxカーネル2.6では、マルチプロセッサ動作時の効率化のために、割り込みコンテキストの遅延処理はすべてtaskletに書き直し、プロセスコンテキストの遅延処理のためにworkqueueを導入しました。
今回の統合のきっかけとなったのは、tasklet実行後に発生するuse-after-freeが問題 *1 となったことでしたが、過去にはtaskletがソフト割り込みコンテキストで実行されること自体が、正確なスケジューリングを妨げる・プロセスの処理完了を遅らせる原因になるとして問題に挙げられることもあったようです。今回の統合によって、taskletはAPIとしては廃止され、再びWQと統合されましたが、taskletたる所以であるソフト割り込みコンテキストにおける処理の遅延実行は仕組みとして残されました。このソフト割り込み処理において発生する遅延に対して、今後カーネルがどう取り組むのか筆者は気になっています。
{kind=link}
コメント