

こちらの書籍ですが、ありがたいことに監訳の金本さん(@kkatsuyoshi)からご献本いただきました!金本さんとは『AI王〜クイズAI日本一決定戦』というイベントでお世話になったことがあり、金本さんが参加者、私が運営委員という感じの関係です。
AI王 は ChatGPT が登場する以前の RAG コンペティション(具体的には、選択肢付き機械読解、オープンドメイン質問応答、etc…)です。当時から興味深い手法を試されており、特に言語モデルが苦手とする固有表現の知識獲得に対する post-hoc なアプローチが勉強になったことを覚えてます。
実践 LLMアプリケーション開発 ―プロトタイプを脱却し、実用的な実装に迫るための包括的な手引き
Suhas Pai 著、金本 勝吉 監訳、オライリー・ジャパン編集部 訳発行年月日 2025年09月
PRINT LENGTH 400
原書 Designing Large Language Model Applications
Print 4,620円
TL;DR
タイトルのとおり、LLMアプリケーション開発の手引きを包括的に解説しています。LLM を計算資源上で学習/推論するための基礎知識から、RAG やエージェントなどの実践知識まで、代表的な論文や公式ドキュメントを引用しながら丁寧に解説されてます📘
LLMアプリケーションでは(タスク|ユーザ|システム)特性に応じた柔軟な設計 が重要になります。
導入では書籍内で紹介される技術をツールと称して『手段(=手札)』と位置づけています。本書を読み進めることで、まずは自身の手札を増やし、さらには、どのような状況/タイミングで手札を切るべきか、という柔軟な意思決定をサポートしてくれる一冊になるかと思います。
どんな人におすすめの書籍か?
自然言語処理や生成AIを俯瞰して学びたい方、LLM を用いたアプリケーション開発を実務でおこなう方、AIエンジニアを目指す方におすすめです!
-
LLMの全体像を理解したい … 1,3部
-
AIアプリケーションを開発したい … 3部
-
LLMを構築したい … 1,2部
-
研究に役立てたい … 1~3部
プログラミング/生成AI 初学者にとっては少し難しい内容になっているかもしれません。ただ Google Colab でのコードが提供されているので、基礎知識があれば安心して学べます 🙌
目次
以下の通りです。ページ数が限られているため一つの知識を深掘りする内容ではないですが、それでも満足感のあるボリュームです。
第1部 LLMの構成要素
1章 イントロダクション
1.1 LLMの定義
1.2 LLMの略史
1.2.1 黎明期
1.2.2 LLMの時代
1.3 LLMのインパクト
1.4 企業におけるLLMの活用
1.5 プロンプティング
1.5.1 ゼロショット・プロンプティング
1.5.2 フューショット・プロンプティング
1.5.3 CoTプロンプティング
1.5.4 プロンプトの連鎖
1.5.5 敵対的プロンプティング
1.6 APIを通してLLMにアクセスする
1.7 LLMの強みと限界
1.8 最初のチャットボット・プロトタイプを作る
1.9 プロトタイプからプロダクションへ
1.10 まとめ
2章 事前学習(Pre-Training)データ
2.1 LLMの構成要素
2.2 事前学習データの要件
2.3 よく使われる事前学習データセット
2.4 合成事前学習データ
2.5 訓練データの前処理
2.5.1 データのフィルタリングとクリーニング
2.5.2 質の高い文書を選ぶ
2.5.3 重複排除
2.5.4 個人識別情報の除去
2.5.5 評価セットの混入除去
2.5.6 データの混合
2.6 下流タスクに対する事前学習データの効果
2.7 事前学習データセットにおけるバイアスと公平性の問題
2.8 まとめ
3章 語彙とトークン化
3.1 語彙
3.2 トークナイザー
3.3 トークン化パイプライン
3.3.1 正規化
3.3.2 プリトークン化
3.3.3 トークン化
3.3.4 後処理
3.3.5 特殊トークン
3.4 まとめ
4章 アーキテクチャと学習目的
4.1 予備知識
4.2 意味を表現する
4.3 Transformerのアーキテクチャ
4.3.1 自己注意
4.3.2 位置符号化(Positional Encoding)
4.3.3 フィードフォワード・ネットワーク
4.3.4 レイヤー正規化
4.4 損失関数(Loss Function)
4.5 内在的モデル評価
4.6 Transformerの中核となるアーキテクチャ
4.6.1 エンコーダのみのアーキテクチャ
4.6.2 エンコーダ・デコーダのアーキテクチャ
4.6.3 デコーダのみのアーキテクチャ
4.6.4 混合エキスパート(MoE)モデル
4.7 学習目的(Learning Objective)
4.7.1 完全言語モデリング
4.7.2 接頭辞言語モデリング
4.7.3 マスク言語モデリング
4.7.4 どの学習目的が優れているのか?
4.8 事前学習モデル
4.9 まとめ
第2部 LLMの活用
5章 LLMをユースケースに合わせる
5.1 LLMの世界をナビゲートする
5.1.1 LLMプロバイダーとは?
5.1.2 モデルの調整とその特色
5.1.3 オープンソースLLM
5.2 タスクに合わせたLLMの選び方
5.2.1 オープンソースLLMとプロプライエタリLLMの比較
5.2.2 LLMの評価
5.3 LLMをロードする
5.3.1 Hugging Face Accelerate
5.3.2 Ollama
5.3.3 LLM推論API
5.4 デコーディング戦略
5.4.1 貪欲なデコーディング
5.4.2 ビームサーチ
5.4.3 Top-kサンプリング
5.4.4 Top-pサンプリング
5.5 LLMで推論を実行する
5.6 構造化された出力(Structured Output)
5.7 モデルのデバッグと解釈可能性
5.8 まとめ
6章 ファインチューニング
6.1 ファインチューニングの必要性
6.2 ファインチューニング:最初から最後まで実施する例
6.2.1 学習アルゴリズムのパラメータ
6.2.2 メモリ最適化パラメータ
6.2.3 正則化パラメータ
6.2.4 バッチサイズ
6.2.5 PEFT
6.2.6 変数の精度を落として作業する
6.2.7 すべてをまとめる
6.3 ファインチューニングのためのデータセット
6.3.1 公開されているインストラクション・チューニング用データセットを活用する
6.3.2 LLMによりインストラクション・チューニング用データセットを生成する
6.4 まとめ
7章 高度なファインチューニング手法
7.1 継続事前学習
7.1.1 リプレイ/メモリ
7.1.2 パラメータ拡張
7.2 PEFT
7.2.1 新しい重みを追加する
7.2.2 サブセット・メソッド(Subset Method)
7.3 複数のモデルを組み合わせる
7.3.1 モデル・アンサンブル
7.3.2 モデルマージ/フュージョン
7.3.3 アダプターのマージ
7.4 まとめ
8章 アライメントと論理的推論
8.1 アライメントの定義
8.2 強化学習
8.2.1 人間によるフィードバックの種類
8.2.2 RLHFの例
8.3 ハルシネーション
8.4 ハルシネーションを軽減する
8.4.1 自己整合性
8.4.2 検証の連鎖
8.4.3 Recitation
8.4.4 ハルシネーションに対処するためのサンプリング手法
8.4.5 レイヤーを対照させたデコーディング
8.5 コンテキスト内ハルシネーション
8.6 無関係な情報によるハルシネーション
8.7 論理的推論
8.7.1 演繹的推論
8.7.2 帰納的推論
8.7.3 アブダクション推論
8.7.4 常識的推論
8.8 LLMに論理的推論を促す
8.8.1 検証器による論理的推論能力の向上
8.8.2 推論時の計算量スケーリング
8.8.3 論理的推論のためのファインチューニング
8.9 まとめ
9章 推論の最適化
9.1 LLMによる推論の課題
9.2 推論を最適化する手法
9.3 計算量を削減する手法
9.3.1 KVキャッシュ
9.3.2 早期終了
9.3.3 知識蒸留
9.4 デコーディングを高速化する手法
9.4.1 投機的デコーディング
9.4.2 並列デコーディング(Parallel Decoding)
9.5 メモリの使用量を減らす手法
9.5.1 対称量子化(Symmetric Quantization)
9.5.2 非対称量子化
9.6 まとめ
第3部 LLMアプリケーションのパラダイム
10章 LLMから外部ツールを利用する
10.1 LLMにおける相互作用のパラダイム
10.1.1 受動的アプローチ
10.1.2 明示的アプローチ
10.1.3 自律的アプローチ
10.2 エージェントの定義
10.3 エージェント型ワークフロー
10.4 エージェント型システムの構成要素
10.4.1 モデル
10.4.2 ツール
10.4.3 データストア
10.4.4 エージェント・ループ
10.4.5 ガードレールと検証器
10.4.6 オーケストレーション・ソフトウェア
10.5 まとめ
11章 表現学習と埋め込み
11.1 埋め込み表現入門
11.2 意味検索
11.3 類似度の測定方法
11.4 埋め込みモデルのファインチューニング
11.4.1 ベースモデル
11.4.2 訓練データセット
11.4.3 損失関数
11.5 指示に基づく埋め込み表現
11.6 埋め込みベクトルの容量を最適化する
11.6.1 マトリョーシカ埋め込み
11.6.2 バイナリおよび整数による埋め込み表現
11.6.3 直積量子化
11.7 チャンク分割(Chunking)
11.7.1 スライディング・ウィンドウを用いたチャンク分割
11.7.2 メタデータを利用したチャンク分割
11.7.3 レイアウトを利用したチャンク分割
11.7.4 意味的なチャンク分割
11.7.5 レイトチャンク分割
11.8 ベクトルデータベース
11.9 埋め込み表現の解釈
11.10 まとめ
12章 RAG
12.1 RAGの必要性
12.2 RAGを利用する場面
12.3 RAGを使うべきかの判断
12.4 RAGのパイプライン
12.4.1 書き換え
12.4.2 検索
12.4.3 リランク
12.4.4 リファイン
12.4.5 挿入
12.4.6 生成
12.5 RAGを用いた記憶の管理
12.6 RAGによるフューショット学習用の事例の選定
12.7 モデルの訓練におけるRAGの利用
12.8 RAGの限界
12.9 RAGとロング・コンテキストのどちらを使うべきか?
12.10 RAGとファインチューニングのどちらを使うべきか?
12.11 まとめ
13章 デザインパターンとシステムアーキテクチャ
13.1 マルチLLMアーキテクチャ
13.1.1 LLMカスケード
13.1.2 ルーター
13.1.3 タスク特化型LLM
13.2 プログラミングパラダイム
13.2.1 DSPy
13.2.2 LMQL
13.3 まとめ
第1部 LLMの構成要素
第1章 イントロダクション
第1章では「LLM とはなにか?」からはじまり、LLM のインパクトや活用例について述べられています。近年の LLM ブームに寄り添った内容で、簡単なプロンプト手法や Gradio を用いたチャットボットの構築についても紹介されています。
また LLM には知能や機能的な言語能力が不足していること、ハルシネーションやコンタミネーション、AIが生成されたテキストへの判別の難しさにも触れ、本書がこうした 課題への正しい理解を獲得するための位置づけである ことが述べられています。
第2章 事前学習(Pre-Training)データ
第2章では「LLMがどのようにして作られるか?」について、事前学習の視点で語られています。代表的な事前学習データセットのほか、質の高い文書を選ぶための前処理パイプラインや、(KL-divergence | Classifier | Perplexity)ベースのアプローチも紹介され、モデルを学習する方が参照したい内容となっています。
特に LLMのセキュリティ脆弱性やバイアス・公平性の問題 についても言及されており、個人的にはこの箇所だけでも読む価値があるなと思いました。
第3章 語彙とトークン化
第3章では「計算機がどのようにして言語を扱うか?」についてトークン視点で紹介されています。Byte-Pair Encoding、Wordpiece、トークナイザの評価(Fertility, Parity)など基礎的な内容について学べます。
研究し始めた頃「BPEも知らないのか」といわれて泣いた記憶があるので、あらためて勉強できてよかったです。(注:実際には泣いてないです
第4章 アーキテクチャと学習目的
第4章では、「入力テキストがどのようにネットワークを伝搬するか?」ついて掘り下げています。重みや活性化関数などの Deep Neural Network の構成要素や分布仮説から整理し、Transformer のアーキテクチャを丁寧に解説しています。
自己注意機構のしくみや位置符号化の種類、クロスエントロピー、Denoiser、Mixture-of-Experts だけでなく、言語モデルのアーキテクチャ(Encoder | Decoder | Encoder-Decoder)や学習目的(Full LM | Prefix LM | Masked LM)別の pros/cons など幅広くカバーされており、Transformer の教科書として参照できそう な内容が続きます。
第2部 LLMの活用
第5章 LLMをユースケースに合わせる
5章では、「ユースケースに合わせて LLM を使用する」を中心に、(OpenAI | Google | Anthropic | etc…)の LLM プロバイダ、(指示チューニング | Reinforcement Learning from Human Feedback; RLFH | ロングコンテキストモデル | ドメイン適応モデル)など、それぞれの特徴が紹介されていました。
また多様な LLM を選ぶための手がかりとして、リーダーボード(Open LLM Leaderboard | Holistic Evaluation of Language Models; HELM)の特徴や、Language Model Evaluation Harness について紹介されています。また Mixed Precision(FP32 | FP16 | BF16, | INT8 | FP8/FP4)、Accelerate、Ollama など、実際に LLM をローカルな環境で使用する際のポイント についても述べられています。
(ビームサーチ | Top-k サンプリング | Top-pサンプリング)や構造化出力(Jsonformer | LMQL | Guidance)などのデコーディング戦略については、OpenAI API など普段から使用されている方にも 学びになる内容となっています。
さらに オープンソースLLMのライセンス についても言及されており、ここも必須で読みたい内容です。
第6章 ファインチューニング
6章では「LLM を学習する」をテーマに、(Optimizer | Learning Rate | Scheduler | Gradient Checkpoint | Gradient Accumulation | Quantization | Label Smoothing | Batch Size )など ファインチューニングにおける基礎知識 が紹介されています。特に Scheduler については(constant | constant_w_warmup | cosine annealing | consine_w_restarts | linear)の学習率推移が図で表示されており、直感的な挙動が確認できます。
さらに Parameter-Efficient Fine-Tuning; PEFT として Low-Rank Adaptation; LoRA の主要なハイパーパラメータ、bitsandbytes ライブラリの紹介があったり、Transformer Reinforcement Learning; TRL を用いたファインチューニングの実行 ができたりもします。
指示チューニング用の合成データセットの作成や、どのように指示付データセットを構築すると良いかなど、効果的な学習データセットの構築 にも言及されていてとても勉強になりました。
第7章 高度なファインチューニング手法
7章では「LLMの重みをなぜ更新するか」について問い、各側面での実現手段(ドメイン適応, タスク適応, 知識の更新, 制御性/追従性)について紹介しています。
はじめに継続事前学習における適応について、Domain-Adaptive Pretraining; DAPT, Task-Adaptive Pretraining; TAPT, 生涯にわたって定期的な学習の継続(Lifelong Learning)について紹介し、破壊的忘却という問題についても言及しています。同時に破壊的忘却を軽減するための取り組みとして、リプレイ/プレイ, 蒸留, 正則化, パラメータ拡張についても紹介しています。
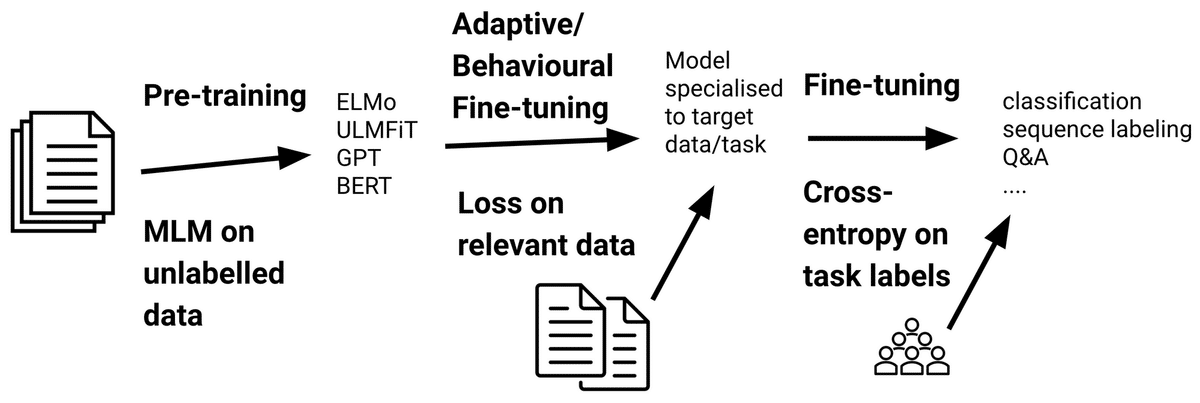
Ruder – Recent Advances in Language Model Fine-tuning [link]
また Parameter-Efficient Fine-Tuning; PEFT について、①新しい重みを追加する ②重みの一部を選択する ③Low-Rank行列を使用する方法についても紹介しています。①の新しい重みを追加する方法では Adapter, Prefix Tuning, Prompt Tuning を取り上げています。
複数のモデルを組み合わせる手法としてアンサンブル(LLM-Blender における Pair-Ranker, GenFuser)やモデルマージについても言及されています。
8章 アライメントと論理的推論
8章では「モデルが望ましい出力をするにはどうしたら良いか」について提起し、 Helpful, Honest, and Harmless; HHH を遵守した理想的な状態に近づけるための手法を紹介しています。
強化学習として、Reinforcement Learning from Human Feedback; RLFH の種類や構成について解説し、TRL RewardTrainer, PPOTrainer による RLFH 実行例 も提示されています。
またハルシネーションについては、どう軽減すればよいかの方針を示し、その具体的な手法として Chain-of-Verification; CoVe, Recitation といったプロンプトベースの手法、Factual-Nucleus Sampling といったサンプリングベースの手法、Decoding by Contrasting Layers; DoLa というでコーディングベースの手法をそれぞれ紹介しています。
また後半では論理的推論の形式(演繹的推論, 帰納的推論, アブダクション)についてそれぞれ紹介し「LLM に論理的推論を促すにはどうしたらよいか」を解説しています。具体的には検証器を持ちいた Iterative Backprompting, Top-k Guessing、推論時の計算量を拡張する Inference-Time Computing、ファインチューニングによる論理思考の獲得について述べています。
9章 推論の最適化
9章では、計算量, メモリ容量, 消費電力といった問題に対して「LLM の推論をどのように効率化するか」について、計算量の削減, デコーディング高速化, メモリ使用量の軽減などについて紹介しています。
計算量削減については、KV-Cache によるコンテキストのキャッシュ、中間層での出力を最終出力として解釈する Early Exit、知識蒸留について丁寧に紹介しています。
またデコーディングを高速化する手法として Speculative Decoding, Parallel Decoding、メモリ使用量を減らす手法として Symmetric Quantization, Asymmetric Quantization についても紹介しています。
第3部 LLMアプリケーションのパラダイム
10章 LLMから外部ツールを利用する
10章では「LLMにタスクをどう解かせるか」をテーマに、近年の応用分野について迫っています。LLMエージェントやワークフロー、ガードレールの種類や再試行戦略、LLM-as-a-Judge の検証項目などを紹介しています。
また共感した箇所を抜粋します。特別なことが書かれている訳ではありません。
LLM にあるタスクを解かせたいとき、取りうる選択肢はいくつかあります。
・LLMが、自身の重みに符号化された記憶と能力を使ってタスクを解く。
・タスクを解くうえで必要なすべてのコンテキストをプロンプトに与え、LLMがその提供されたコンテキストと自身の能力を使って解決する。
・LLMがそのタスクを解くのに必要な情報や能力を十分に持っていない場合、ファインチューニングなどを通じてモデルの重みを更新し、必要な能力や知識が利用できるようにする。
・タスクを解くうえで必要なコンテキストがあらかじめわからない場合には、関連するコンテキストを自動的に取得し、それをプロンプトに挿入する仕組みを使う。
・タスクを解くために、どのような外部ツールやデータストアを用いるかをあらかじめ明示的に LLM に指示し、LLM がそれに従って処理を進める。
・LLM自身が、必要に応じてタスクを複数のサブタスクに分解し、環境とのやりとりを通じて必要な情報や知識を集めながら、それらのサブタスクを解いていく。もし自力で解決できない場合は、外部のモデルやツールに任せる。
冒頭でも述べたように、LLMアプリケーションでは『タスク・ユーザ・システム 特性に応じた柔軟な設計』が重要になります。
近年では RAG や AIエージェント が流行していますが、大事なのはこれらは「手段」であり「二の次」ということです。AIエージェントにこだわるあまり課題解決という目的を見失うと辛いキムチ(辛い気持ち)になってしまいます。
11章 表現学習と埋め込み
11章では「文章を表現するためのベクトル」について解説されています。表現学習に始まり、ベクトル表現をどう学習・取得するか(エンコーダベースの言語モデル|最終層のプーリング)、文と文の類似度のはかり方について、それぞれ紹介されています。
また Sentence Transformers ライブラリを用いたファインチューニング(学習データの構築, 損失関数)、指示・説明に基づく検索、ベクトル容量の最適化(マトリョーシカ埋め込み, 量子化, 直積量子化)、最大系列長を考慮したチャンク分割(トークン数|メタデータ/レイアウト|セマンティックチャンク|レイトチャンク)など、実践のために身につけたい基礎知識 も解説されています。
12章 RAG
12章では「Retrieval Augmented Generation; RAG」について、活用場面や下図のような全体図を含めて解説しています。
RAG は関連する文書をどう取得するかの『検索』が一般的に重要ですが、その工夫についても触れています。ハイブリッド検索や Cross/Dual -Encoder 、ColBERT のような Late Interaction について。また HyDE や Chain-of-Note のような生成プロセスを伴う検索や、Query Likelihood Model、RankVicuna の学習プロセス生成的検索についても解説しています。
LLM がロングコンテキストを扱えるようになったことで「RAG の時代は終了した」と耳にすることもありますが、本書ではその棲み分けや限界 についても述べられています。RAG という手段は、AIエージェントにおいてもツール呼び出しやメモリ管理に利用されているので注目の章かと思います。
13章 デザインパターンとシステムアーキテクチャ
13章は「LLMアプリケーションの設計パターン」を紹介しています。LLMごとに異なるサブタスクを解かせる or 全ての LLM が同じタスクを解くなど、どのようなタスク特性の場合に、どう設計すればよいか の手がかりを学べます。具体的には LLMカスケード、ルーター、タスク特化型LLM というコンパウンドAIシステムとしての設計パターンを紹介しています。
また開発段階での反復的な改善を抽象化することを目指した DSPy の紹介、プログラミングを用いた手法で LLM を開発するための堅牢な基盤を提供する LMQL の紹介もされています。
おわりに
私個人、自然言語処理を専攻 → アプリケーション開発、という経歴であるため全ての章において学びが多く、とても参考になりました!
またコラムも興味深い内容が多かったのが印象的でした:
-
インストラクションチューニングの副作用
-
Eloレーティングの偏り
-
継続事前学習における学習率の決め方
-
ファインチューニングは新たな能力を学ぶのか?
-
Weak-to-Strong Generalization
-
モデルマージは望ましくない特性を除去できるか?
-
etc…
書籍についてはページボリュームが多く、鈍器としてもご利用いただけると思います。本屋に訪れた際は、ぜひ一度手に取ってみてください 🤲
以上『実践LLMアプリケーション開発』レビューでした。最後までお読みいただき、ありがとうございました!
Source link
{kind=link}
コメント