

こんにちは、ソーシャル経済メディア「NewsPicks」のプラットフォームエンジニアリングチームの崔(ちぇ)です。前回の記事で、複雑になりすぎたシステムをシンプルにするための設計をしてみたというお話をしました。
今回は、その続編として、実装を進めてみて浮上した課題をどのように解決し、結果的にどれほど便利なものになったのかについてお話ししようと思います。
結論を先に共有しますと、仮説通りに一ヶ月くらいかかるだろう作業が数日で完了するという快挙を果たしました!さらには、特に気にしなくても勝手にパフォーマンスが担保された形で機能開発できることも確認できました!
前編に書いた、弊社が抱えていた問題をまとめると以下の二つです。
- お掃除する余裕のない開発体制
- 要件の積み重なりで開発しにくくなったシステム(類似する機能なのに毎回新たに開発していた)
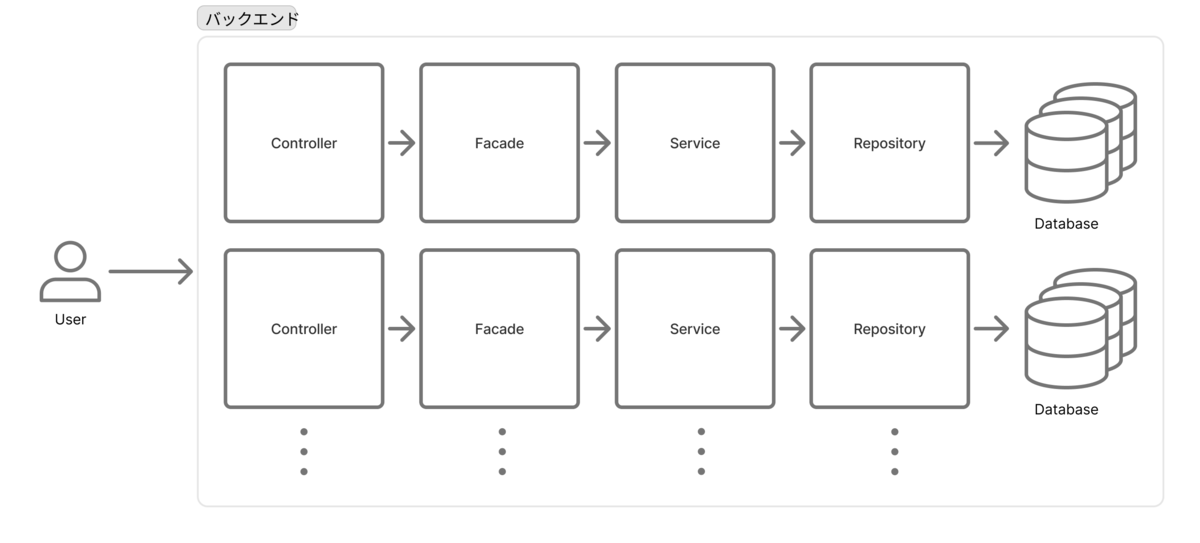
これらの問題を解決すべく、以下のような変革を起こしました。
- お掃除する余裕のない開発体制 → 開発生産性・業務効率化を主担当とするプラットフォームエンジニアリングチームの発足
- 要件の積み重なりで開発しにくくなったシステム → 全体的なシステム設計のやり直し
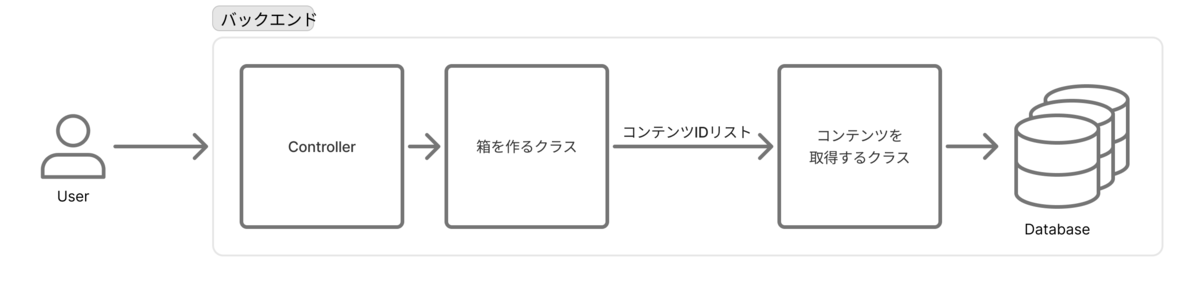
上記の設計で実際組み込もうとしたところ、全体的な流れはそのままでよかったものの、いくつかの更なる工夫が必要だとわかりました。それらをこれからご紹介します。
課題1)別の層にあるクラスにアクセスができない
上記の設計図に登場するクラスやモジュールは全て、ビジネスロジックに関わる部分なので、ビジネスロジック層に実装しました。すると、データアクセス層にあるリポジトリクラスのメソッドが呼び出せないという問題に遭遇しました。ビジネスロジック層がもっとコアな部分にあったためです。

こういう時は、インタフェースだけビジネスロジック層に移行もしくは実装すればアクセスできるようになります。

課題2)I/O処理の回数がN+1になっている
今回のシステム改善は、毎回同じ処理を実装しなくてもいいようにしたい!を実現するためです。しかし、それだけでは足りなくて、毎回パフォーマンスチェックをせずとも安心してさっと実装できるシステムにもなってほしいのです。
パフォーマンスを落とす実装を見ると、多くの場合、I/O処理の回数がN+1になっています。
例えば、以下の fetch 関数は、呼び出し側からすると、引数としてコレクションを受け取っているためI/O回数が1に見えます。しかし、実は内部でループを回しており、無駄にデータベースに頻繁にアクセスしちゃっています。こういう実装は、コレクションのサイズによっては、莫大な時間とコストをかけてしまうのでやってはいけません!
fun fetch(targetIds: List<Int>): List<Target> { return targetIds.map { someProcess(it) } }
なので、今回のプロジェクトでは、各データベースに1回だけアクセスするメソッドを用意するところから始めました。
DynamoDBを使う場合
弊社ではデータベースとして、DynamoDBやRDSを利用します。
まず、DynamoDBの場合データを格納しているテーブルに主キーが設定されている場合、batchGetItem で効率的に取得することが可能です。
FYI
DynamoDBは分散キー・バリューのストアなので、アイテムはパーティションキーとソートキーの組み合わせ(主キー)を特定できるようにしています。逆に、主キーが設定されていない部分に関しては、特定することができず全体をスキャンする必要があります。
その他の使用可否の条件については公式ドキュメントをご参照ください。
import aws.sdk.kotlin.services.dynamodb.DynamoDbClient import aws.sdk.kotlin.services.dynamodb.model.AttributeValue import aws.sdk.kotlin.services.dynamodb.model.BatchGetItemRequest val keyAndAttributeList = listOf( mapOf("contentId" to AttributeValue.N("12345")), mapOf("contentId" to AttributeValue.N("67890")), ) val request = BatchGetItemRequest { requestItems = mapOf( "Contents" to KeysAndAttributes { this.keys = keyAndAttributeList } ) } val client = DynamoDbClient { region = "ap-northeast-1" } val response = dynamoDbClient.batchGetItem(request) val items = response.responses?.get(tableName) ?: emptyList()
RDSを使う場合
RDSはリレーショナルデータベースなので、効率的に複数のデータを一気に取得するクエリを書くだけでN+1を防ぐことができます。Hibernateの createQuery を使えば、以下のようにクエリが実行できます。新目のAPIだと createSelectionQuery や createMutationQuery というのが使えます。
import org.hibernate.SessionFactory import path.to.model.Content val targetIds = listOf(12345, 67890) val session = SessionFactory.getCurrentSession() val items = session.createQuery( """ from Contents where id in (:targetIds) """.trimIndent(), Content::class.java ) .setParameter("targetIds", targetIds) .setMaxResults(20) .list()
Redisを使う場合
弊社では、キャッシュの保存のためにRedisを利用します。Redisの場合、executePipelined を使えば一回の通信の中で繰り返しデータを取り出し、最終的にはコレクションとして返します。これでN+1問題から解放されます。注意すべきは下記の2点です。
executePipelinedのコールバック関数は必ずnullを返す必要がある- 最終的な結果は、
RedisOperationsの呼び出し時にコレクトされ、executePipelinedの戻り値として取得、必要な型にキャストされるため、型を明記する必要がある
import org.springframework.data.redis.core.RedisTemplate import org.springframework.data.redis.core.RedisOperations import org.springframework.stereotype.Component @Component class RedisRepository( redis: RedisOperations<String, String>, ) { fun get(ids: List<Int>, limit: Int): Map<Int, List<Int>> { val scores = redis.executePipelined { connection -> targetIds.forEach { connection.zRevRangeWithScores(it, 0, -1) } null }.map { it as SetString>> } return ids.zip(scores) .associate { (id, scoreSet) -> id to scoreSet.mapNotNull { it.value?.toInt() }.take(limit) } } }
課題3)既存のものと類似する画面を作る際にはほぼ何もしなくてもいいようにしたい
前編で触れたのですが、NewsPicksには多様なタブがあり、それぞれ別のロジックで作られています。
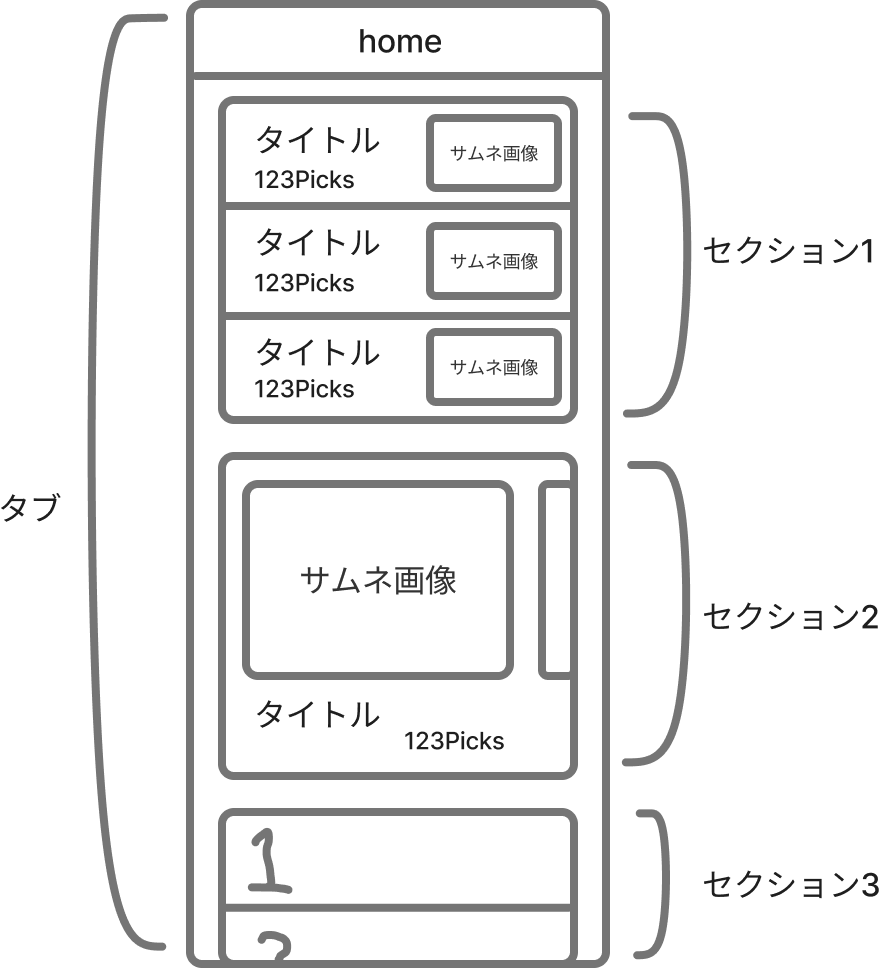
FYI
- タブ: 異なる複数のセクションを表示するインタフェース要素
- セクション: コンテンツをリストやカルーセルなどでまとめて表示したインタフェース要素
複雑な仕様を持つサービスを開発するスピードを上げるには、単純にやることや考えることを減らせる作りにすればいいです。そこで考えたのが、データベースにタブやセクションの定義を登録しておくことです。タブを作る処理は、データベースから取得した定義をもとに画面を作ります。そうすれば、開発者が手を加えることないのではと!
タブにはいろんなセクションがあり、セクションにはいろんなコンテンツが表示されます。それを表現するためにデータベースにコンテンツのIDをいちいち記載しておくわけにはいきません。なので、データベースにはどうやってコンテンツを取得すればいいのかを登録することにしました。
具体的な方法としては、コンテンツ取得に必要な情報をまとめたJSONを作るのです。例えば、ある動画シリーズの直近のエピソードが欲しいとしましょう。データベースには以下のようなJSONを入れておきます。
{ "key": 11, # シリーズIDが11 "size": 20, # フェッチサイズが20 "moduleType": "MovieSeriesEpisodes" # コンテンツID一覧を取得するクラス名 }
以下のようなエンティティクラスを用意し、データベースからタブとセクションの定義を取得します。
@Entity @Table("section_definition") data class SectionDefinition( @Id @GeneratedValue(strategy = GenerationType.IDENTITY) val id: Int? = null, ... @Column(columnDefinition = "json") val algorithm: String, )
JSONにある moduleType として指定された MovieSeriesEpisodes は以下のように定義されています。(JSONで定義したものを、SectionAlgorithmと称しています)
@JsonTypeInfo(use = JsonTypeInfo.Id.NAME, property = "moduleType") sealed interface SectionAlgorithm { @get:JsonIgnore val module: KClass<out DisplayTargetFinderModule> val size: Int } data class MovieSeriesEpisodes(val key: Int, override val size: Int): SectionAlgorithm { override val module KClass<out DisplayTargetFinderModule> get() = MovieSeriesEpisodesModule::class } inline fun <reified T> String.convert(): T { val mapper = ObjectMapper() return mapper.readValue(this) }
Jackson の ObjectMapper を活用すれば、[JSON → オブジェクト] の変換処理が容易に実装できます。
今後、JSONのキー(上記の SectionAlgorithm のパラメータ)が追加されることを念頭において、 DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES を false にしておくことをお勧めします。
import com.fasterxml.jackson.databind.ObjectMapper val mapper = ObjectMapper() val entity = sectionSettingRepository.findByCode(code) val algorithm = mapper.readValue(entity.algorithm)
これで、新シリーズのエピソードを表示するセクションが作りたい場合は、以下のようなJSONをデータベースに登録しておくだけでお仕事完了です!
{ "key": 101, "size": 20, "moduleType": "MovieSeriesEpisodes" }
課題4)毎回API(場合によってはコントローラーも)を作らないといけない状況を打破したい
今まで新機能を作るとなると、APIの設計からしないといけませんでした。パスはどうするんだ、パラメータはどうするんだ、返り値はどうするんだなどをバックエンドチームとフロントエンドチームとで議論し、新たに作らないといけなかったのです。
そういうコストもできればかけて欲しくありませんでした。それで、汎用的なAPIを用意し、タブの識別子(文字列)くらいを決めれば済むようにしました。
リクエスト時に柔軟にパラメータが渡せるようにしたい
画面によってはパラメータが必要な場合、不要な場合があります。例えば、NewsPicksの検索ホーム画面(左)は、みんなに同じコンテンツを表示するので、パラメータを受け取る必要がありません。一方で、検索結果画面(右)だと、検索キーワードや絞り込みの条件をパラメータとして受け取る必要があります。


javaxの HttpServletRequest を引数として受け取るようにすると、コントローラーにクエリパラメータを羅列しなくても取り出して使えるようになります。それをファサード層やサービス層まで渡せば、タブごとに必要な情報をパラメータで受け渡しできます。
@RestController @RequestMapping("/universal-tabs") class UniversalFeedController(...) : ControllerBase() { @GetMapping("/{tabCode}") fun getFeed( @PathVariable tabCode: String, @RequestParam(value = "cursor", required = false) cursor: String?, request: HttpServletRequest, ): UniversalTabDto { ... return createTab(tabCode, request, cursor) } }
内部では以下のように取り出します。
fun extractParam(request: HttpServletRequest): Parameters { val parameterMap = request.parameterMap.mapValues { it.value.toList() } val keyword = parameterMap["keyword"]?.firstOrNull() ?: throw IllegalArgumentException("keyword is required")
必要な情報だけレスポンスとして返したい
当初は、以下のようなコンテンツモデルを、レスポンスとして返す箱に詰めようと思いました。NewsModel や MovieModel は記事や動画を表現するのに必要なすべてのプロパティを持たせています。つまり、サーバーとしては色々提供するので、必要に応じてフロント側で取り出して使ってください、という設計にしていました。
data class NewsContent( val id: Int, val model: NewsModel, ) data class MovieContent( val id: Int, val news: NewsModel, val model: MovieModel, ) data class NewsModel( val id: Int, val title: String, val thumbnailUrl: String, val published: ZonedDateTime, ... )
しかし、全てのデータを渡すのは、ほとんどの画面において不要なものが無駄に多く、通信を重くするだけというのがわかりました。
レスポンスの型に合わせてエンドポイントやコントローラーを分けてしまったら、現状と同じくコントローラーが量産されてしまうので(開発のコストがかかるので)嬉しくありません。
そこで、同じデザインのセクションであれば要求するデータも同じであろうことから、デザイン別レスポンス型を決めました。そのセクションがなんのデザインなのかは、データベースのセクション定義に定めておきます。
@RestController @RequestMapping("/universal-tabs") class UniversalFeedController(...) : ControllerBase() { @GetMapping("/{tabCode}") fun getFeed( @PathVariable tabCode: String, @RequestParam(value = "cursor", required = false) cursor: String?, request: HttpServletRequest, ): UniversalTabDto { ... return createTab(tabCode, request, cursor).toUniversalTabDto() } }
fun Tab.toUniversalTabDto(): UniversalTabDto = UniversalTabDto( code = this.code, sections = this.sections.map { it.toUniversalTabSection() }, ... )
fun Section.toUniversalTabSection(): UniversalTabSection = when (this.design) { SectionDesign.CONTENT_CAROUSEL -> this.toContentCarouselSection() ... else -> throw IllegalArgumentException("Unsupported section design: ${this.design}") }
課題5)汎用的なAPIにしたら、New Relic で正しくモニタリングができなくなっちゃった
弊社では、パフォーマンスチェックなどのためにNew Relicを利用しています。New Relicでは、エンドポイント単位でトランザクションが記録されます。
FYI
New RelicはAPM(Application Performance Monitoring)というパフォーマンスモニタリング用のツールを提供します。APMでは「トランザクション」を監視するのですが、New Relicでは「トランザクション」をソフトウェアアプリケーション内の一つの論理作業単位を表現する言葉として使っています。
わかりやすく書くと、ユーザーがリクエストしてサーバーからレスポオンすが返ってくるまでの処理が「トランザクション」です。New Relicは各トランザクションを自動で記録し、LatencyやAvailabilityを可視化します。
- Latency: レスポンスを返すまでにどれくらいの時間がかかったか
- Availability: エラーが発生せずユーザーが正常に使用できているか
一つのエンドポイントで汎用的にいろんなリクエストを処理しようとしたら、New Relicのトランザクションもまとまってしまいました。タブ区別なく記録されてしまっては、正しくパフォーマンスのモニタリンができません。
New Relicの setTransactionName メソッドを使えば、パスパラメータで受け取るタブの識別子ごとにトランザクションを分けることができます。
import com.newrelic.api.agent.NewRelic import com.newrelic.api.agent.TransactionNamePriority @RestController @RequestMapping("/universal-tabs") class UnifiedFeedController( ... ) : ControllerBase() { @GetMapping("/{tabCode}") fun getFeed( @PathVariable tabCode: String, ... ): UnifiedFeedDto { setTransactionName(tabCode) return createTab(tabCode, request, cursor).toUniversalTabDto() } private fun setTransactionName(tabCode: String) { NewRelic.getAgent().transaction.setTransactionName( TransactionNamePriority.CUSTOM_HIGH, true, "SpringController" "universal-tabs/${tabCode} (GET)", ) } }
リファレンス実装として既存の機能を一つ置き換え、新機能も一つ作りました。
当初は「便利なものを作っていろんなところで広報したのだから、きっとみんな使ってくれるでしょう!」と安易に思っていました。しかし、思っていたようなムーブは起きませんでした。
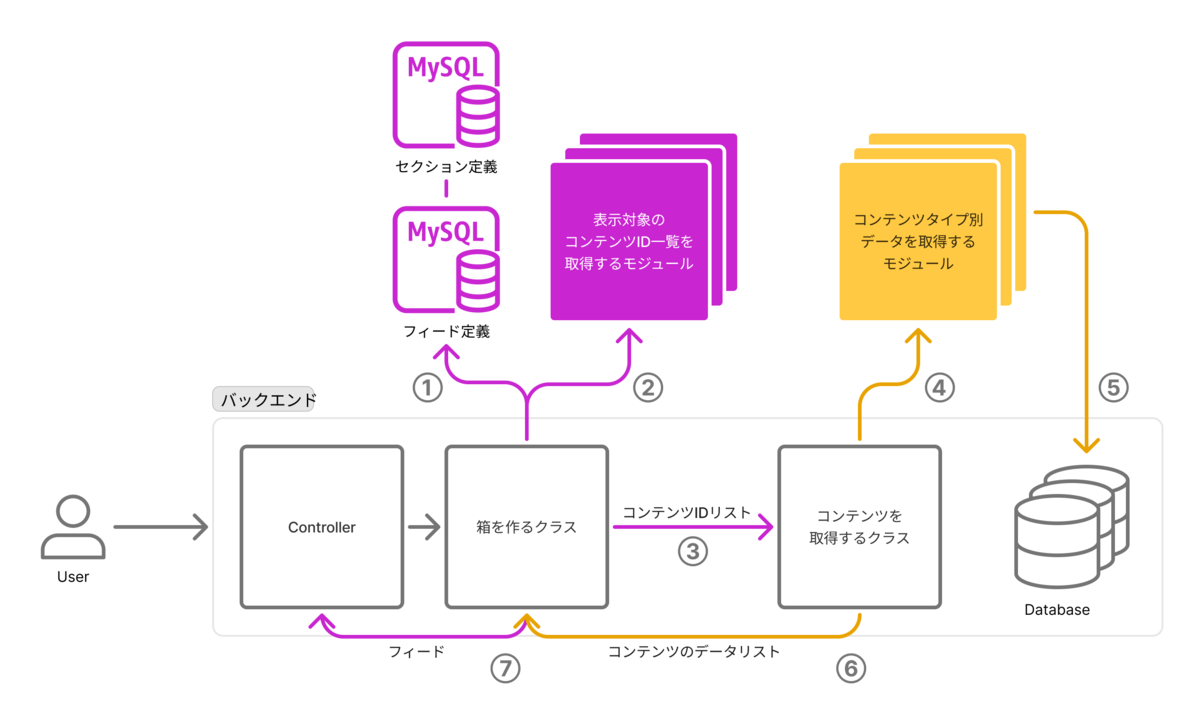
かなり抽象的な実装になったので、初見の人はコードを読むだけで、どこに何を追加実装すればやりたいことができるのかがぱっと見わかりにくかったのです。「XXするクラス」を理解しなくても、追加実装は下図の②や④だけで済むのですが、それがパッとわからない状態でした。
それで、これから施策チームは何を開発しようとするのかを確認し、「これ使ってみませんか!これなら工数あまり使わなくても作れますよ!サポートします、ペアプロします!」と営業をしました。
MTGをセットし、軽く設計を共有し、やるべきことを箇条書きで共有したところ「めっちゃ便利そう!」という反応をいただきました。
FYI: 当時共有した内容
汎用的なAPIの設計
このAPIを使えば、新機能追加のために追加実装が必要なのは以下のみです!
- データベースにタブとセクションの定義を追加
- (リファレンス実装で作ったもので対応できない画面だったので)②を追加
- リポジトリーの追加(コレクション対応版のメソッドは用意されてるので、それを呼び出すようにしてください)
作っておけば勝手に変革が起きるのではなく、使ってもらえるように動かないと、自分で起こさないといけないということを学びました。
実際、1〜2時間くらいのペアプロを3回ほど行い、新機能が完成しました!ペアプロ以外にも実装が必要だったかもしれませんが、だいたいその時間に収まっていたと思われます。
New Relicで確認した、レスポンスを返すまでの処理時間も平均300ms程度に収まっていて、開発者が色々気にしなくてもサクッと作れることが証明できたかなと思います。
これから更なるパフォーマンス改善や、開発生産性向上に貢献し、みなさんに快適にNewsPicksが利用できるよう、努めてまいります!これからも引き続きよろしくお願いいたします。
{kind=link}
コメント