

こんにちは、タイミーでエンジニアをしている徳富です。
今回は、EKS上にGitHub Actions Self-hosted Runner基盤を構築した話をお届けします。
背景:GitHub Actionsへの移行と、新たに見えてきた課題
2024年10月に公開したCI基盤をGitHub Actionsへ移行した記事で紹介したとおり、
CircleCIからGitHub Actionsへの移行によって、私たちのCI体験は大きく改善しました。
しかし、開発者やテストケースが増え、時間が経つにつれて新たな課題も見えてきました。
- 実行回数の急増によるコスト高騰
- 2025年2月頃からDevinをはじめとしたAIエージェントの利用が進み、PRやpushの回数が一気に増加
- 開発者数の増加も重なり、ワークフロー実行回数が比例して伸びていった
- GitHub-hosted Runnerは料金や安定性の面である程度最適化されているため、Self-hostedに切り替えれば必ずしもコスト削減につながるとは限らない。しかし、割引オプションが少なく、コストコントロールが難しいという課題もある
- 一方AWSならSavings PlansやSpotインスタンスなどの仕組みを活用でき、柔軟に最適化が可能。開発者やエージェントの利用増加で実行回数が急増するタイミーのユースケースにおいては、この「柔軟に最適化できる」という点が大きなメリットであることがわかってきました
- テスト時間のじわじわとした増加
- テストケース数の増加により、全体の実行時間も長くなってきている
apt installなどのセットアップ処理にも時間がかかっている- 「ランナーイメージに事前インストールしておけばもっと速くできるのでは?」という声も出始めた
「コストをコントロールしながら、テストももっと速くしたい」
そんな思いから、私たちはSelf-hosted Runner基盤の構築を検討し始めました。
最初のアプローチ:ECS + Lambda構成
当初は ECS + Lambda + API Gateway を組み合わせて、ランナー基盤を構築しようとしました。
しかし実際に検証してみると、すぐにいくつかの課題に直面しました。
-
レートリミットの考慮
1回のCI実行で最大35並列のランナーを起動してます。
日中は多いときで 1時間に60回以上 実行されることもあり、GitHub API の レートリミットを意識した設計が必要になります。→ これを Lambda 側で考慮して実装するのはかなり複雑。
-
ランナーは30秒以内に立ち上がってほしい という要件がある。
- Lambda のコードを継続的にメンテナンスするコストも無視できない。
「長期的に運用するには、この構成は少し複雑すぎるかもしれない」
そう判断し、よりシンプルに運用できる別のアプローチを探すことにしました。
選んだのは EKS(auto mode) × Actions Runner Controller
そこで目をつけたのが、GitHub公式が提供する **Actions Runner Controller(ARC)**。
ARCはGitHub ActionsとKubernetesをつなぎ、必要なときだけランナーPodを動的に起動してくれます。
さらにクラスタ基盤には EKS Auto Mode を採用しました。
ノード管理やスケーリング設定をほとんど自前で持たずに済むため、運用の手間を大幅に減らせるのが魅力です。
「EKS Auto Mode × ARC であれば、管理コストを抑えつつ柔軟なSelf-hosted Runnerが作れるのでは?」
そう考え、この構成で進めることにしました。
アーキテクチャ概要
ざっくりとした構成はこんなイメージです。
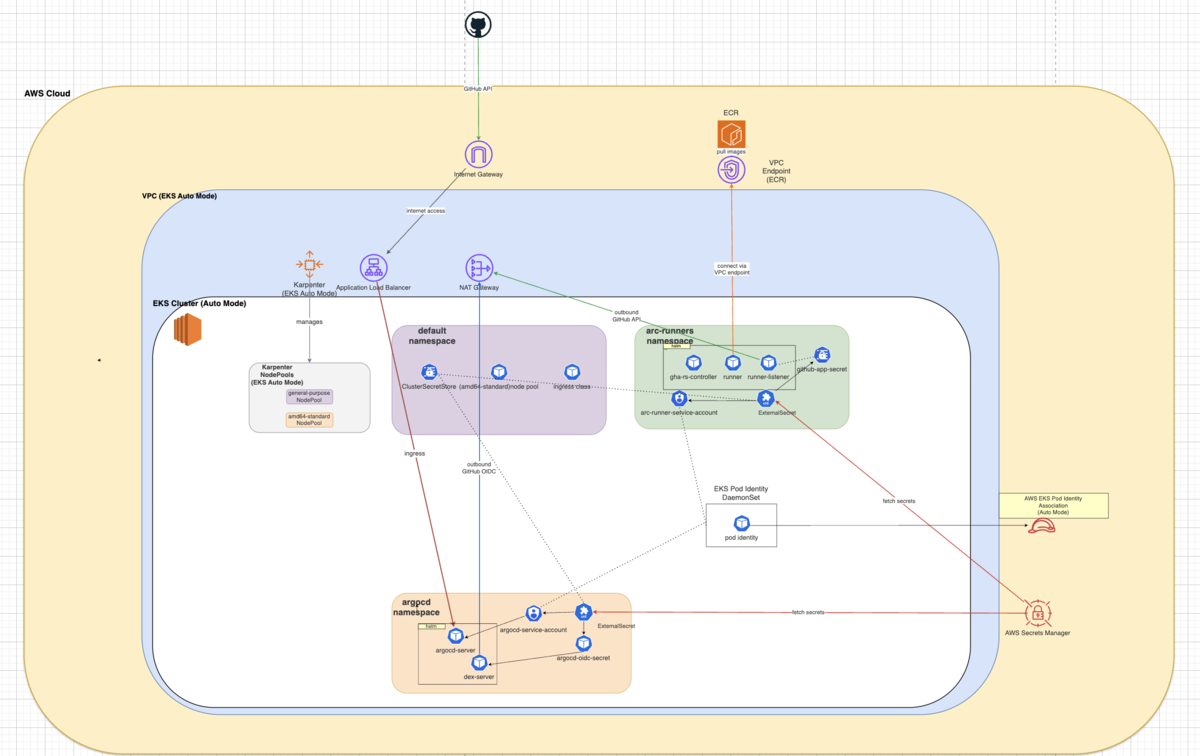
- ARC: GitHub APIと連携し、ランナーPodを自動的に作成・削除
- EKS Auto Mode: クラスタ管理を最小限に抑えつつ、柔軟なスケーリングが可能
- Karpenter: Auto Modeの裏側で働くプロビジョナー。従来のCluster Autoscalerよりnode起動が速い
特にCIのように時間帯によって必要リソースが大きく変動するワークロードでは、
Auto Mode+Karpenterの組み合わせが非常に相性が良く、メンテナンス性・柔軟性の両立ができました。
導入時に直面した課題と解決策
ここからが本番です。
実際に導入を進めていくと、次々と問題が発生しました。
1. Spotインスタンスの安定性問題
当初はコスト削減を狙って、停止率の低いインスタンスタイプの Spotインスタンス を採用していました。
しかし、弊社のCIは 35並列で高頻度に実行されるため、必要なインスタンス数が多くなり、停止確率が低いタイプでも 1日あたり5〜10回ほどノードが落ちることがありました。
その結果、CIが途中で失敗するケースが頻発し、開発者体験を大きく損ねる要因となってしまいました。
対策
そこで思い切って オンデマンドインスタンスに切り替え、必要に応じて Savings Plans を適用する方針にしました。
- オンデマンドにしたことで、ランナーが突然落ちるリスクがなくなり、安定してCIを回せるようになった
- 安定性が向上したことで、CIだけでなく デプロイなど他のワークフローもSelf-hosted Runnerに寄せる ことが可能に
- これによりEC2のアイドル時間を減らし、稼働率を高めることでコスト効率も改善できました
2. スケールインでランナーPodが強制終了する問題
次に直面したのは「EC2のスケールインによって、ランナーPodがCI実行中に突然落ちる」という問題です。
原因は、Karpenterの設定でした。
デフォルトでは disruption.consolidationPolicy が WhenEmptyOrUnderutilized になっており、
ノードのリソース使用率が低いと、Podが稼働中でも容赦なくノードを落としてしまうのです。
(参考: https://karpenter.sh/docs/concepts/disruption/)
対策
consolidationPolicyを WhenEmpty に変更- Podがないノードのみスケールイン対象とするよう設定
spec: disruption: consolidationPolicy: WhenEmpty
これでランナーPodが実行中に消える問題は解消しました。
3. ノードが全然スケールインしない問題
しかし、ここで別の問題が発生します。
「一度スケールアウトすると、ノードがほとんど減らない」という現象です。
原因は Kubernetes のスケジューリング。
Kubernetes のスケジューラには、Pod をできるだけ均等に配置しようとする仕組みがあります。
そのため Pod が複数のノードに分散して配置されやすく、ノード上の Pod が 0 になるケースが少ないため、スケールインがなかなか進まなくなります。
対策
- Pod Affinityを利用し、ランナーPodはなるべく同じノードに詰めるよう設定
- Pod配置の断片化を防ぎ、スケールインしやすくしました
affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchLabels: actions.github.com/scale-set-namespace: arc-runners topologyKey: kubernetes.io/hostname
これによりリソース効率が大きく改善されました。
4. 夜間にリソースを最適化する作戦
リソース効率をさらに高めるため、日中は安定性を優先し、夜間だけ段階的にノードを整理する仕組みを導入しました。
具体的には、disruption.consolidationPolicy を WhenEmptyOrUnderutilized に設定したうえで、夜間に 一定間隔で15分だけpodが存在するノードのスケールインを許可 → その後は再び禁止 というサイクルを繰り返します。
これにより、ノード上にPodが残っていても一気に消されることはなく、「急にPodが落ちてCIが止まる」といったリスクを避けながら、少しずつリソースを最適化できるようになります。
spec: disruption: consolidationPolicy: WhenEmptyOrUnderutilized consolidateAfter: 5m budgets: - nodes: "0" reasons: - Underutilized schedule: "0 0 * * *" duration: "11h45m" - nodes: "0" reasons: - Underutilized schedule: "0 12 * * *" duration: "3h15m" - nodes: "0" reasons: - Underutilized schedule: "30 15 * * *" duration: "1h45m" - nodes: "0" reasons: - Underutilized schedule: "30 17 * * *" duration: "2h45m" - nodes: "0" reasons: - Underutilized schedule: "30 20 * * *" duration: "3h30m"
この仕組みによって、日中は安定してCIを回しつつ、夜間は少しずつノードを整理してリソースを効率的に活用できるようになりました。
5. コールドスタート問題をランナープールで解消
弊社では35並列のランナーを利用しています。
そのため、完全なオンデマンド起動では間に合わず、
ランナー起動待ちが発生してしまうこともありました。
そこで、ARCの minRunners 設定を活用し、ランナープールを作成。
あらかじめ一定数のランナーを起動しておくことで、
要求があればすぐに割り当てられるようになり、
GitHub-hosted runnerと同じ快適な使い心地を実現しました。
5 Runner PodでDockerを使う工夫
最後のハードルは「ランナーPodでDockerをどう使うか」です。
私たちのCIではMySQLやRedisなどのservice containerを多用しているため、RunnerコンテナからDockerを操作できる仕組みが必要でした。
選んだ方法
RunnerでDockerを扱う方法は大きく分けて DooD (Docker outside of Docker) と DinD (Docker in Docker) の2種類があります。(参考:GitHub Actions の self-hosted runner で Docker を使う際のパターン整理)。
今回は DinD を採用しましたが、その中でもさらに実現方法が2パターン存在します。
- Runnerコンテナ内で直接Dockerデーモンを起動する方式
- Runnerコンテナ自身が
dockerdを立ち上げ、docker buildやdocker runを自己完結的に実行する。 - シンプルですが、Runnerコンテナに 特権モードや大量の権限 を付与する必要があるため、セキュリティ面での懸念が残ります。
- また、RunnerコンテナとDockerデーモンが同居することでリソース管理が複雑化しやすく、トラブルシュートもしづらいという課題があります。
- Runnerコンテナ自身が
- Dockerデーモンをサイドカーとして起動する方式
- Pod内で Runner と
dockerdを分離し、emptyDirなどを介して ソケット通信 させる。 - Dockerの実行環境はサイドカーに閉じるため、Runnerコンテナは通常権限で動かせる。
- CIジョブ終了とともにPodごと削除されるため、イメージやボリュームなどの作業痕が自動的に掃除される点もメリットです。
- Pod内で Runner と
私たちは Runnerコンテナに強い権限を持たせないことを重視し、後者の DinDサイドカー方式 を選択しました。
まとめと次回予告
今回、EKS × ARC を使ってGitHub Actions Self-hosted Runner基盤を構築し、
コスト・パフォーマンス・柔軟性のいいバランスで実現できました。
ただ、これで終わりではありません。
次回は、この基盤の上でテスト実行時間をさらに短縮するために行ったチューニングについて詳しく紹介する予定です。
「GitHub-hosted runnerで限界を感じている」
「EKSでSelf-hosted Runnerを検討している」
そんな方の参考になればうれしいです。
{kind=link}
コメント