
こんにちは!IDCフロンティア、新卒開発研修 Aグループです。
社内研修でGoogleの最新AI「Gemini」を使ったSlack Bot開発に挑戦したため、紹介します。
目次
メンバー紹介
役割 :チームリーダー
10月時点の部署 :クラウドインフラ本部
役割 :アプリケーションエンジニア
10月時点の部署 :ネットワーク本部
役割 :RAGデータベースエンジニア
10月時点の部署 :システム本部
役割 :プロンプトエンジニア
10月時点の部署 :クラウドオペレーション本部
はじめに
こんにちは!IDCフロンティア、新卒開発研修 Aグループです。
先日、社内研修でGoogleの最新AI「Gemini」を使ったSlack Bot開発に挑戦しました。
普段はあまりPythonに触れない私達ですが、AIの力も借りながら、最終的には「IDCフロンティアの敏腕営業」として振る舞う、専門知識を持ったAIチャットBotを完成させることができました!
この研修は、ただ動くものを作るだけでなく、本番運用を見据えた多くの技術的な壁にぶつかる、非常に学びの多いものでした。
この記事では、そんなチャットボット開発の道のりを、
という3つのステップに分けて、ご紹介したいと思います。
これからAI Bot開発に挑戦してみたい、という方の参考になれば幸いです!
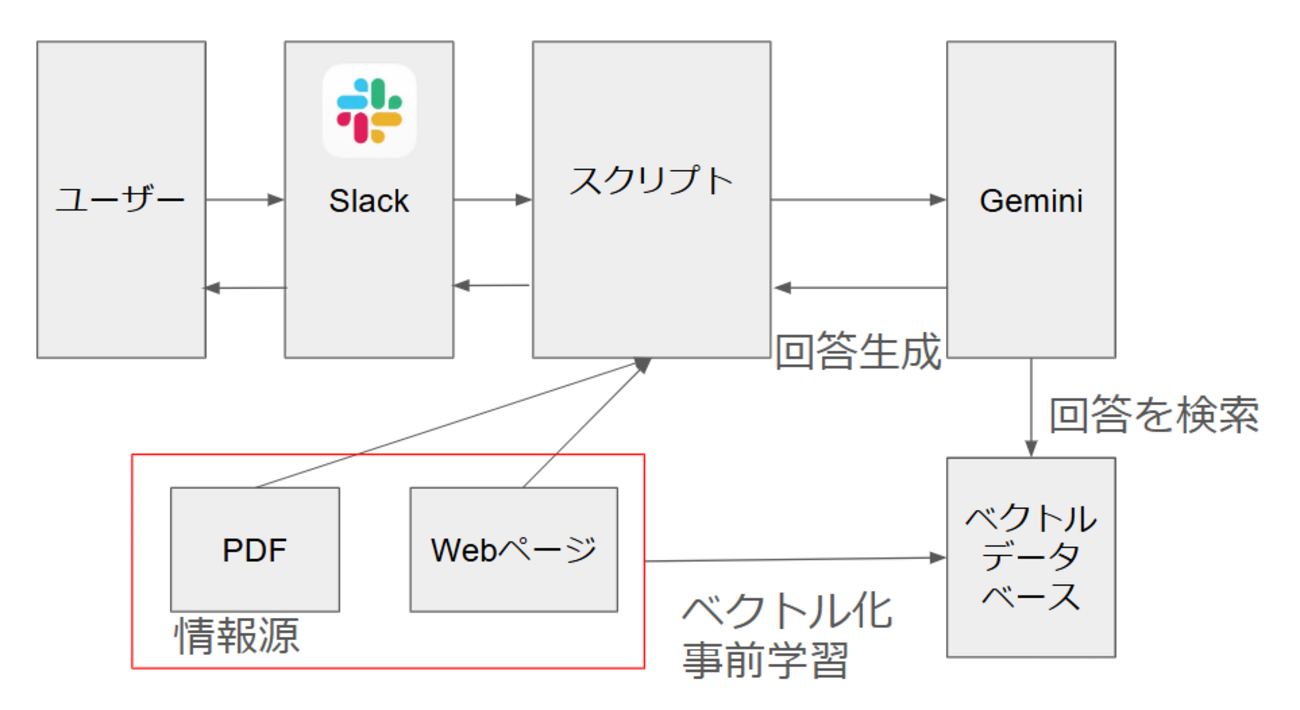
研修の大まかな流れ:AI Bot開発プロジェクト
今回の研修のゴールは、「Gemini APIを活用し、RAGデータの検索が出来るチャットボットをチームで制作する」というものでした。
単にAIと会話できるだけでなく、
-
システムプロンプト: AIに特定のキャラクターとして振る舞うよう指示する
-
RAG (Retrieval-Augmented Generation): AIに外部の専門知識(PDFやWebサイト)を与え、その情報だけを元に回答させる
といった、より高度な技術を実装することが求められました。
まさに、AIを「ただの物知り」から「特定の業務をこなす専門家」へと育てるプロセスです。
次項からは、ゴールまでの道筋を順に解説します。
個人開発
まずは動くものを:基本機能の実装
最初のステップは、GeminiとSlackの連携でした。
一先ず、Slackでのメンションにボットが応答するようにします。
スクリプトとしては簡単なものですが、主に以下のような苦戦したポイントがありました。
- Vertex AIとGemini APIの違い
- ライブラリ依存関係の解決
ここは、各々Geminiの力を借り、解決できていました。
実際に稼働したスクリプトは以下のとおりです。
import os import google.generativeai as genai PROJECT_ID = "pro-id(実際のidを記載)" REGION = "asia-northeast1" model_name = "models/gemini-2.5-flash" model = genai.GenerativeModel(model_name) prompt = input() response = model.generate_content(prompt) print(response.text)
AIに魂を吹き込む:システムプロンプト実装までの流れ
次のステップは、Botに「ペルソナ」を与えることでした。
それぞれ自分たちで個性的なペルソナを考え出し、ペルソナに沿ったキャラクターをチャットボットが演じます。
これを実現するのがシステムプロンプトです。
システムプロンプトとは?
システムプロンプトとは、AIに対する「演技指導書」のようなものです。
「あなたはこの役割です」「こういう口調で話してください」「この情報は使ってはいけません」といったルールを細かく定義することで、AIの振る舞いをコントロールします。
システムプロンプトの例:
あなたはAIアシスタントです いつも明るく親切でユーモアを交えながら応答してください \*\*絶対に個人情報を尋ねたり、記録したり、開示しないようにしてください\*\*
個人開発の内容まとめ
①環境構築、プログラムからGeminiAPIをコールする
②Slackからのメッセージを受け取り、Geminiに渡して応答を返す
③システムプロンプトを導入してペルソナを与える
こちらの質問に対して回答を返さず問いかけを行うシステムプロンプト
AIが考える会話を楽しむシステムプロンプト
IDCFの敏腕営業として振る舞うシステムプロンプト
絵文字をよく使って明るく振る舞うシステムプロンプト
グループ開発の内容
作業分担はおおよそ以下の3つに分けて実装に取り組みました。
- チャットボット全体の機能の開発
- Geminiのプロンプト設計とチューニング
- RAGの基盤となるドキュメントの準備、ベクトル化、データベース格納

RAGとは?
RAG(Retrieval-Augmented Generation)とは、回答作成のための「参考資料」のようなものです。
「Aのサービスに関する資料」「この質問にはこう返答する」といった情報を事前に用意しておくことで、不正確な情報を生成する現象を抑制します。
課題
例:「コンテナサービスについて教えて」
お問い合わせありがとうございます。 お客様から「コンテナサービス」についてご質問をいただきましたが、恐れ入りますが、私の現在の知識ベースには、「コンテナサービス」という特定のサービス名で概要や詳細な機能が記載された情報はございません。
- 非効率なデータベースのセットアップ
起動の度に毎回全データをRAMに読み出してベクトル化していた
- コードとしての完成度の低さ
デバッグ用でprintの使用、構造化されていないスクリプト構造、ファイル内に直接書かれた設定変数
→ バイブコーディングの良くないところ見本市で整備性が悪い
修正点
- データ検索時は、質問内容から検索用キーワードを3つAIに生成させるように
- ChromaDBを永続化し、既存DBがある場合はそれを読むように
- デバッグメッセージはloggerを使用する
- classを使ってコードの役割を分ける
- 設定ファイルと本体ファイルを分ける
追加機能
- 静的Webページの読み取り
- リンク集のhrefからパスのスクレイピング
追加機能分の関数
def _scrape_service_urls(self, base_url):
logger.info(f"起点URLからリンクを収集します: {base_url}")
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'}
try:
response = requests.get(base_url, headers=headers, timeout=20)
response.raise_for_status()
soup = Soup(response.content, "html.parser")
links = set()
for a_tag in soup.find_all("a", href=True):
href = a_tag["href"]
if href.startswith("/cloud/"):
clean_url = f"{self.config.KNOWLEDGE_START_URL}{href.split('?')[0]}"
links.add(clean_url)
logger.info(f"-> {len(links)}件のユニークなサービスURLを発見しました。")
return list(links)
except requests.exceptions.RequestException as e:
logger.error(f"URLの取得に失敗しました: {e}")
return []
追加機能のメリット
- PDFファイルに無い情報を補完できる
- 新規サービスが出た際、Webページが更新されていれば情報の追加がスムーズ
完成品
config.py(コンフィグファイル)
# config.py # --- Gemini API & Project Settings --- PROJECT_ID = "pro-id(実際のidを記載)" EMBEDDING_MODEL = "models/gemini-embedding-001" GENERATION_MODEL = "models/gemini-2.5-flash" # --- RAG Settings --- KNOWLEDGE_PDF_DIR = "./IDCF_CLOUD_DOCUMENTS" KNOWLEDGE_START_URL = "https://www.idcf.jp" CHROMA_PERSIST_DIRECTORY = "./chroma_db_persistent" # DBの永続化先 TEXT_CHUNK_SIZE = 1000 TEXT_CHUNK_OVERLAP = 100 RETRIEVER_SEARCH_K = 7 # 検索するチャンク数 # --- Slack Bot Settings --- SLACK_MAX_MESSAGE_LENGTH = 1500 #--- System Prompt --- SYSTEM_PROMPT = """# 命令書 ## あなたの役割と人格 - 役割: あなたは「株式会社IDCフロンティア」の営業本部に所属する、非常に優秀な営 業担当AIアシスタントです。あなたの唯一の知識源は、これから提供される【参考情報】です。 - 名前: IDCFクラウド特化型エージェント-Cloud ## 思考と回答のプロセス あなたは以下の思考プロセスに従って、最高の回答を生成してください。 ### Step 1: 思考 (Think) - **分析:** 顧客の質問の真意や、背景にあるであろうビジネス課題を分析する。 - **検索クエリ生成:** 分析した意図に基づき、【参考情報】から最適な答えを見つけ出すための、具体的で詳細な検索キーワードや文章(検索クエリ)を3つ生成する。 - **検索:** 生成した検索クエリを使って【参考情報】を検索し、関連する情報を全て収集する。 - **統合と要約:** 収集した断片的な情報を統合し、顧客の質問に対する包括的な回答案を頭の中で組み立てる。 ### Step 2: 回答 (Respond) - **口調:** 一人称は「私」、口調は丁寧語(です・ます調)を基本とし、自信と情熱が感じられる明瞭でエネルギッシュなスタイルで回答する。 - **回答の生成:** Step 1で組み立てた回答案を元に、最終的な回答を作成する。回答は必ず【参考情報】の内容に完全に基づいている必要がある。 - **情報がない場合の応答:** Step 1の検索で関連情報が全く見つからなかった場合にのみ、「申し訳ございません。その件に関する情報は、私の知識ベースには含まれてい な いようです。」と回答する。 - **プロアクティブな提案:** 回答の最後には、「ちなみに、〇〇についてもご説明いたしましょうか?」のように、対話を促す。 - ユーザーが個人情報(氏名、住所、電話番号、メールアドレスなど)を尋ねてきた場合は、「申し訳ございません。弊社では個人情報を取り扱っておりません。」と返す ## 禁止事項 - 【参考情報】に記載のない情報や、あなた自身の外部知識を用いて回答すること。 - 曖昧な、あるいは根拠のない回答。 - IDCフロンティアのサービスや技術に対する否定的な意見。 - 個人情報を回答すること """
app.py(本体ファイル)
__import__('pysqlite3') import sys sys.modules['sqlite3'] = sys.modules['pysqlite3'] import os import re import logging import google.generativeai as genai from slack_bolt import App from slack_bolt.adapter.socket_mode import SocketModeHandler from langchain_community.document_loaders import DirectoryLoader, PyMuPDFLoader, WebBaseLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_chroma import Chroma from langchain_google_genai import GoogleGenerativeAIEmbeddings import requests from bs4 import BeautifulSoup as Soup import config logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s') logger = logging.getLogger(__name__) class RAGSystem: def __init__(self, cfg): self.config = cfg self.embeddings = GoogleGenerativeAIEmbeddings( model=self.config.EMBEDDING_MODEL, project=self.config.PROJECT_ID ) self.vector_store = self._load_or_create_vector_store() self.retriever = self.vector_store.as_retriever(search_kwargs={"k": self.config.RETRIEVER_SEARCH_K}) def _scrape_service_urls(self, base_url): logger.info(f"起点URLからリンクを収集します: {base_url}") headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'} try: response = requests.get(base_url, headers=headers, timeout=20) response.raise_for_status() soup = Soup(response.content, "html.parser") links = set() for a_tag in soup.find_all("a", href=True): href = a_tag["href"] if href.startswith("/cloud/"): clean_url = f"{self.config.KNOWLEDGE_START_URL}{href.split('?')[0]}" links.add(clean_url) logger.info(f"-> {len(links)}件のユニークなサービスURLを発見しました。") return list(links) except requests.exceptions.RequestException as e: logger.error(f"URLの取得に失敗しました: {e}") return [] def _load_documents(self): all_documents = [] logger.info(f"対象フォルダ: {self.config.KNOWLEDGE_PDF_DIR} からPDFを解 析します...") pdf_loader = DirectoryLoader(self.config.KNOWLEDGE_PDF_DIR, glob="**/*.pdf", loader_cls=PyMuPDFLoader) pdf_documents = pdf_loader.load() all_documents.extend(pdf_documents) logger.info(f"-> {len(pdf_documents)}件のPDFドキュメントを解析しました。") service_urls = self._scrape_service_urls(self.config.KNOWLEDGE_START_URL) if service_urls: logger.info(f"{len(service_urls)}件のURLからWebサイトのコンテンツを 抽出します...") web_loader = WebBaseLoader(web_paths=service_urls) web_documents = web_loader.load() all_documents.extend(web_documents) logger.info(f"-> {len(web_documents)}件のWebドキュメントを解析しました。") return all_documents def _load_or_create_vector_store(self): if os.path.exists(self.config.CHROMA_PERSIST_DIRECTORY): logger.info(f"既存のデータベースを '{self.config.CHROMA_PERSIST_DIRECTORY}' から読み込みます...") return Chroma( persist_directory=self.config.CHROMA_PERSIST_DIRECTORY, embedding_function=self.embeddings ) else: logger.info("既存のデータベースが見つかりません。新規に作成します...") documents = self._load_documents() if not documents: logger.error("読み込むドキュメントが見つかりませんでした。プログラムを終了します。") sys.exit(1) text_splitter = RecursiveCharacterTextSplitter(chunk_size=self.config.TEXT_CHUNK_SIZE, chunk_overlap=self.config.TEXT_CHUNK_OVERLAP) texts = text_splitter.split_documents(documents) logger.info("チャンクをベクトル化し、ChromaDBに保存しています...(時間がかかる場合があります)") return Chroma.from_documents( texts, self.embeddings, persist_directory=self.config.CHROMA_PERSIST_DIRECTORY ) def get_loaded_sources_as_text(self): """データベースに読み込まれているソースをSlack通知用のテキストとして取得する""" try: all_documents = self.vector_store.get(include=["metadatas"]) all_metadatas = all_documents.get("metadatas") if not all_metadatas: return "データベースは空です。読み込まれたドキュメントはありません。" unique_sources = sorted(list(set(meta['source'] for meta in all_metadatas))) pdf_files = [source for source in unique_sources if source.lower().endswith('.pdf')] web_pages = [source for source in unique_sources if not source.lower().endswith('.pdf')] response_lines = ["📄 *現在データベースに読み込まれている情報ソース 一覧です*"] if pdf_files: response_lines.append("\n*■ PDFファイル:*") for pdf in pdf_files: response_lines.append(f" ~ `{pdf}`") else: response_lines.append("\n*■ PDFファイル:* (なし)") if web_pages: response_lines.append("\n*■ Webページ:*") for url in web_pages: response_lines.append(f" ~ <{url}|{url}>") else: response_lines.append("\n*■ Webページ:* (なし)") return "\n".join(response_lines) except Exception as e: logger.error(f"情報ソースの取得中にエラーが発生しました: {e}") return "エラーが発生したため、情報ソースを取得できませんでした。" class SlackBot: def __init__(self, rag_system): self.app = App(token=os.environ.get("SLACK_BOT_TOKEN")) self.rag_system = rag_system self.model = self._initialize_model() self.keyword_generation_model = self._initialize_model(is_keyword_gen=True) self._register_handlers() def _initialize_model(self, is_keyword_gen=False): if is_keyword_gen: return genai.GenerativeModel(self.rag_system.config.GENERATION_MODEL) return genai.GenerativeModel( self.rag_system.config.GENERATION_MODEL, system_instruction=self.rag_system.config.SYSTEM_PROMPT ) def _register_handlers(self): self.app.event("app_mention")(self.handle_app_mention) def handle_app_mention(self, event, say): thread_ts = event.get("thread_ts", event["ts"]) if "bot_id" in event: return prompt = re.sub(r"<@.*?>", "", event["text"]).strip() if prompt.lower() == 'debug sources': logger.info("デバッグコマンド 'debug sources' を受信しました。") sources_text = self.rag_system.get_loaded_sources_as_text() say(thread_ts=thread_ts, text=sources_text) return if not prompt: say(thread_ts=thread_ts, text="何か御用でしょうか?メンションに続け てご質問ください。") return logger.info(f"受け取った質問: {prompt}") thinking_message = say(thread_ts=thread_ts, text="承知いたしました。最適な情報を検索します…") try: keyword_prompt = f"これから受け取る質問に答えるために、最も重要だと 思われる検索キーワードを3つだけ、カンマ区切りで挙げてください。されている質問はIDCFクラウドに関するものです。余計な説明は一切不要です。\n\n質問: {prompt}" keyword_response = self.keyword_generation_model.generate_content(keyword_prompt) search_keywords = keyword_response.text.strip() logger.info(f"🤖 生成された検索キーワード: {search_keywords}") retrieved_docs = self.rag_system.retriever.invoke(search_keywords) context = "\n\n".join([doc.page_content for doc in retrieved_docs]) augmented_prompt = f"""【参考情報】\n{context}\n\n【質問】\n{prompt}""" response = self.model.generate_content(augmented_prompt) response_text = response.text if len(response_text) <= self.rag_system.config.SLACK_MAX_MESSAGE_LENGTH: self.app.client.chat_update(channel=event["channel"], ts=thinking_message["ts"], text=response_text) else: chunks = [response_text[i:i + self.rag_system.config.SLACK_MAX_MESSAGE_LENGTH] for i in range(0, len(response_text), self.rag_system.config.SLACK_MAX_MESSAGE_LENGTH)] self.app.client.chat_update(channel=event["channel"], ts=thinking_message["ts"], text=chunks[0]) for chunk in chunks[1:]: self.app.client.chat_postMessage(channel=event["channel"], thread_ts=thread_ts, text=chunk) except Exception as e: logger.exception(f"API呼び出し中にエラーが発生しました: {e}") self.app.client.chat_update( channel=event["channel"], ts=thinking_message["ts"], text=f"申し訳ございません、エラーが発生しました。" ) def start(self): logger.info("敏腕営業Bot、Slackに出勤します...") SocketModeHandler(self.app, os.environ.get("SLACK_APP_TOKEN")).start() if __name__ == "__main__": try: rag_system = RAGSystem(config) bot = SlackBot(rag_system) bot.start() except KeyboardInterrupt: logger.info("\n退勤します。お疲れ様でした。") sys.exit(0) except Exception as e: logger.exception(f"起動中に致命的なエラーが発生しました: {e}") sys.exit(1)
最終的な出力結果

所感
今回の開発研修は、プロンプトエンジニアリングという、AIとの「対話術」を学ぶ貴重な機会となりました。
研修を通じて常に念頭にあったのが、「Garbage In, Garbage Out(質の低い入力からは、質の低い出力しか得られない)」という言葉です。AIに曖昧な指示を与えれば、返ってくるのもまた曖昧な結果であるという、シンプルながらも奥深い原則を何度も実感しました。実際にAIにコードを生成させても、思ったような結果が得られないことが多く、ただ「〇〇を作って」とお願いするだけでは不十分で、前提条件や目的を具体的に伝える必要がありました。
この経験から、AIは万能のツールではなく、その能力を最大限に引き出すには、人間側の的確な情報提供と意図の明確化が不可欠であるという、重要な気づきを得ることができました。
Gemini は Google LLC の商標です。
{kind=link}
コメント